王红元老师Node课程笔记
浏览器内核和JS引擎
作用是帮助渲染界面和运行JS代码,不同的浏览器有不同的内核

渲染引擎工作的过程
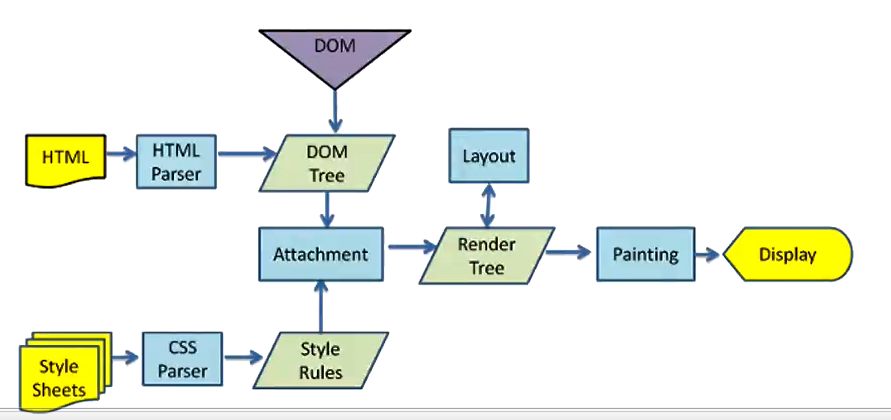
HTML代码经过HTML Parser解析后生成DOM树,CSS代码也是要先经过解析,然后经过Attachment进行附加,最终生成渲染树Render Tree,然后也有一个Layout Tree布局树生成,两者结合后进行绘制。
在这个执行过程,HTML解析遇到了JavaScript标签时,会停止解析HTML,而去加载和执行JavaScript代码。不直接异步加载执行JavaScript代码的原因是,JavaScript代码可以操作DOM,所以浏览器希望HTML解析的DOM和JavaScript操作之后的DOM放到一起来生成最终的DOM树,而不是频繁生成新的DOM树
HTML代码中有
<script>标签,所以需要有JavaScript引擎来执行JavaScript代码(转化成汇编语言,然后再转化成机器语言,然后才能被CPU执行)。浏览器里面包含了JavaScript引擎。比较常见的有SpiderMonkey(第一款)、Chakra、JavaScriptCore(Webkit中的JavaScript引擎)、V8
浏览器内核和JavaScript引擎的关系
以Webkit为例,Webkit事实上是由两部分组成的:
- WebCore:负责HTML解析、布局、渲染等等相关工作;
- JavaScriptCore:解析、执行JavaScript代码
V8引擎
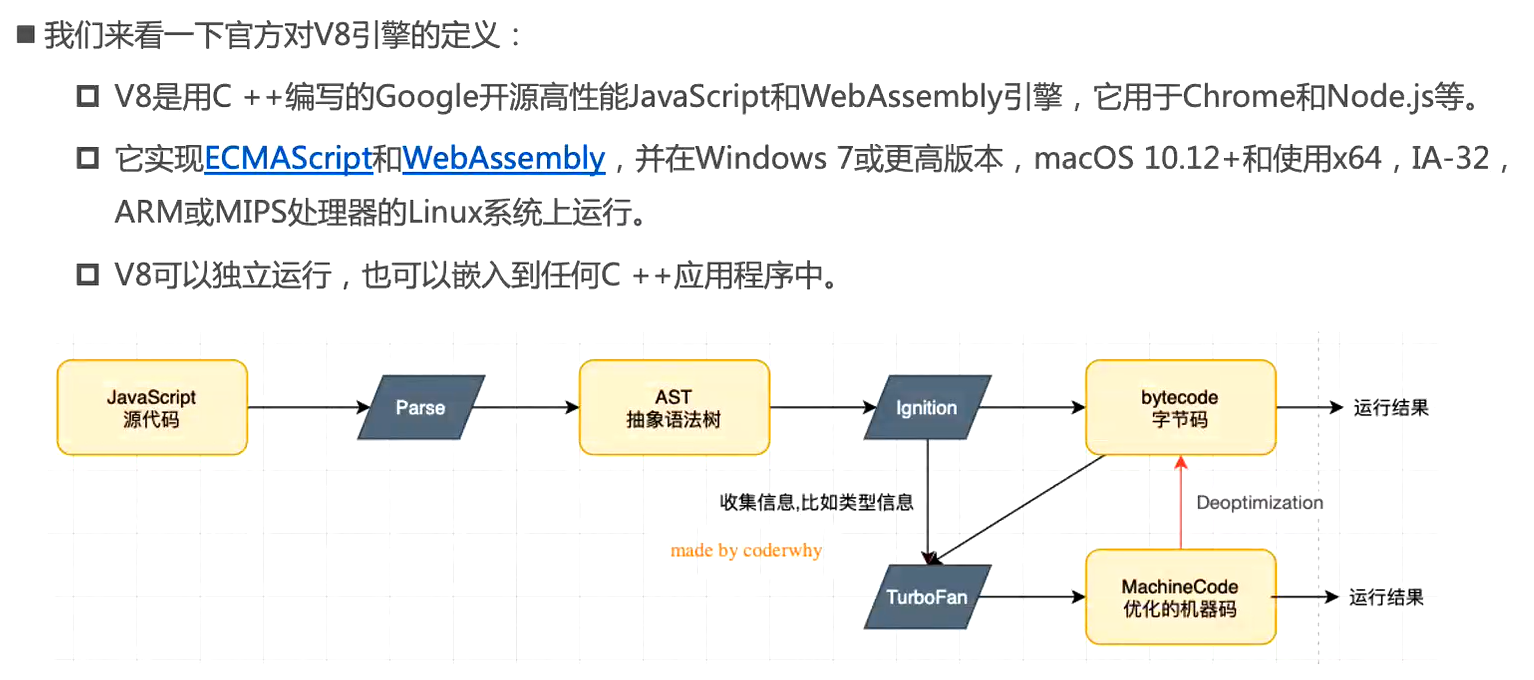
原理

node.js是什么
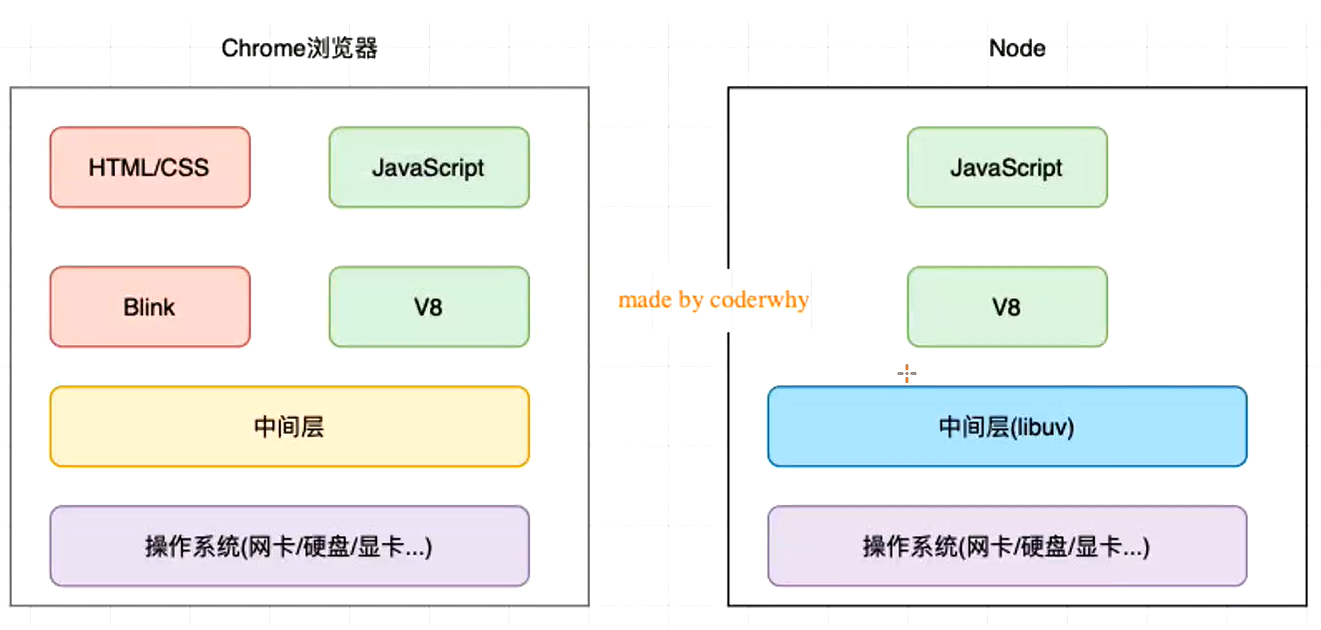
浏览器和Node.js架构区别
Node的REPL
REPL(Read-Eval-Print Loop),翻译为“读取-求值-输出”循环
REPL是一个简单的、交互式的编程环境
在终端中直接敲node就可以进入交互环境,node有例如process(进程)的全局对象
全局对象和模块化开发
Node程序传递参数
执行node程序时若要传参:node 文件名 要传的参数,例如node index.js env=dev coderwhy
在程序中获取传递的参数是在process内置对象中的,里面有一个argv属性,其属性值是一个数组,里面包含了我们需要的参数。然后对process.argv调用数组方法就可以提取出来了
Node的输出
console.log、console.clear清空控制台、console.trace打印函数的调用栈,还有其他console方法
全局对象
常见的全局对象
process对象:process提供了Node进程中相关的信息,比如Node的运行环境、参数信息等
console对象:提供了简单的调试控制台
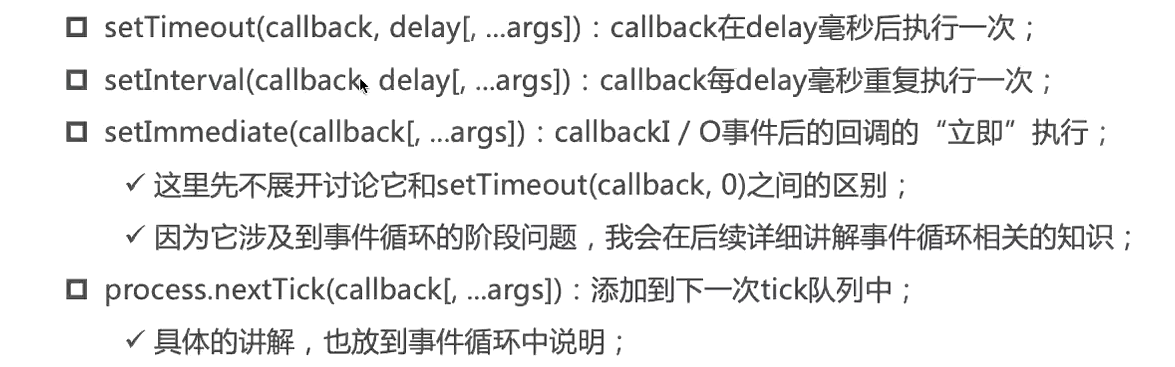
定时器函数:在Node中使用定时器有好几种方法
特殊的全局对象
这些全局对象实际上是模块中的变量,只是每个模块都有,每个模块中的值都是不一样的。在命令行交互中是不可以使用的。包括有:_dirname、_filename、exports、module、require()
global
global是一个全局对象,事实上前端提到的process、console、setTimeout等都有被放到global中。方便拿到一些东西
global有点类似浏览器中的window。在浏览器中, 全局变量都是在window上。
两者区别:
在浏览器中执行的JS代码,如果我们在顶级范围内通过var定义一个属性,默认会被添加到window对象上;但是在node中,我们通过var定义一个属性,它只是在当前模块中有一个变量,不会放到全局
1 | var name = "xxx" |
原因是,在浏览器顶层中写的东西是没有模块的概念,是最顶层的东西,所以会随便放到window上。而在node中,每个文件都是独立的模块。在每个模块中定义的东西如果放在global上可能会出现覆盖,所以在模块中定义的属性是属于模块而不属于全局的。process之所以在local上,是因为在node源码中手动把他放进去了。
JacaScript模块化
模块化的核心是导出和导入
JS是ES6之后才推出自己的模块化方案,在此之前的模块化方案有AMD、CMD、CommonJS等
CommonJS和Node
CommonJS是一个规范,最初提出来实在浏览器之外的地方用的。
Node是CommonJS在服务器端一个具有代表性的实现
Browserify是CommonJS在浏览器的一种实现
webpack打包工具具备对CommonJS的支持和转换
Node中对CommonJS进行了支持和实现,让我们在开发node的过程中可以方便的进行模块化开发
- 在Node中每一个js文件都是一个单独的模块
- 这个模块包括CommonJS规范的核心变量:exports、module.exports、require
- 利用这些变量可以进行模块化开发
exports和module.exports
由维基百科中对于CommonJS规范的解析,CommonJS中是没有module.exports的概念的,但是为了实现模块的导出,Node中使用的是Module的类,每一个模块(每一个js文件)都是Module的一个实例,也就是module。所以在Node中真正用于导出的不是exports而是module.exports,因为module才是导出的真正实现者
node源码里写了module.exports = exports,所以当我们修改exports的时候默认修改了module.exports
1 | //在导出变量的模块 bar.js |
require实质上获取的是module.exports。所以如果当module.exports不再引用exports,那么exports的修改就没有意义了,比如我们额外给module.exports赋值 一个空对象。
赋值在最顶层。
如果在bar.js中添加
exports=111,main.js中打印require的结果,打印的是一个空对象{}
require
require是一个函数,帮助我们引入一个文件(模块)中导出的对象
常见的查找规则:require(X)
X是一个核心模块,比如path、http
- 直接返回核心模块,并停止查找
X是以./或../或/开头的

直接是一个X(没有路径),而且X不是一个核心模块
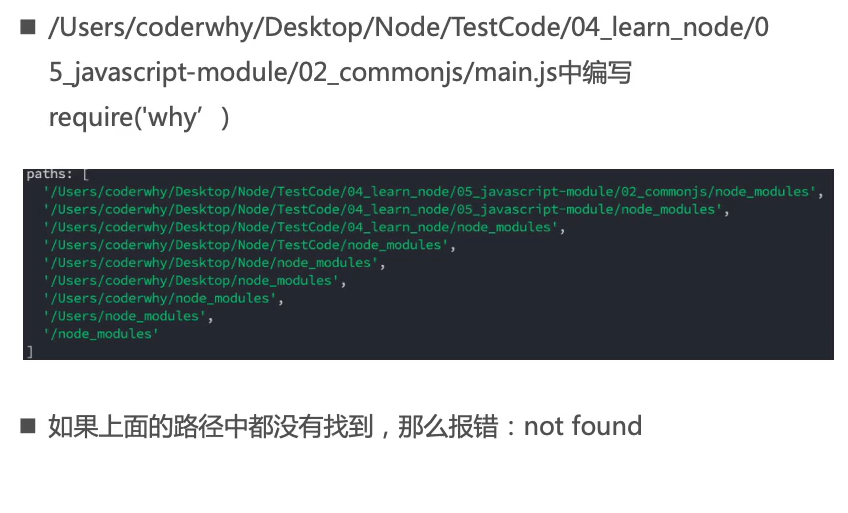
一层一层往上找,这个paths存在于
module对象中
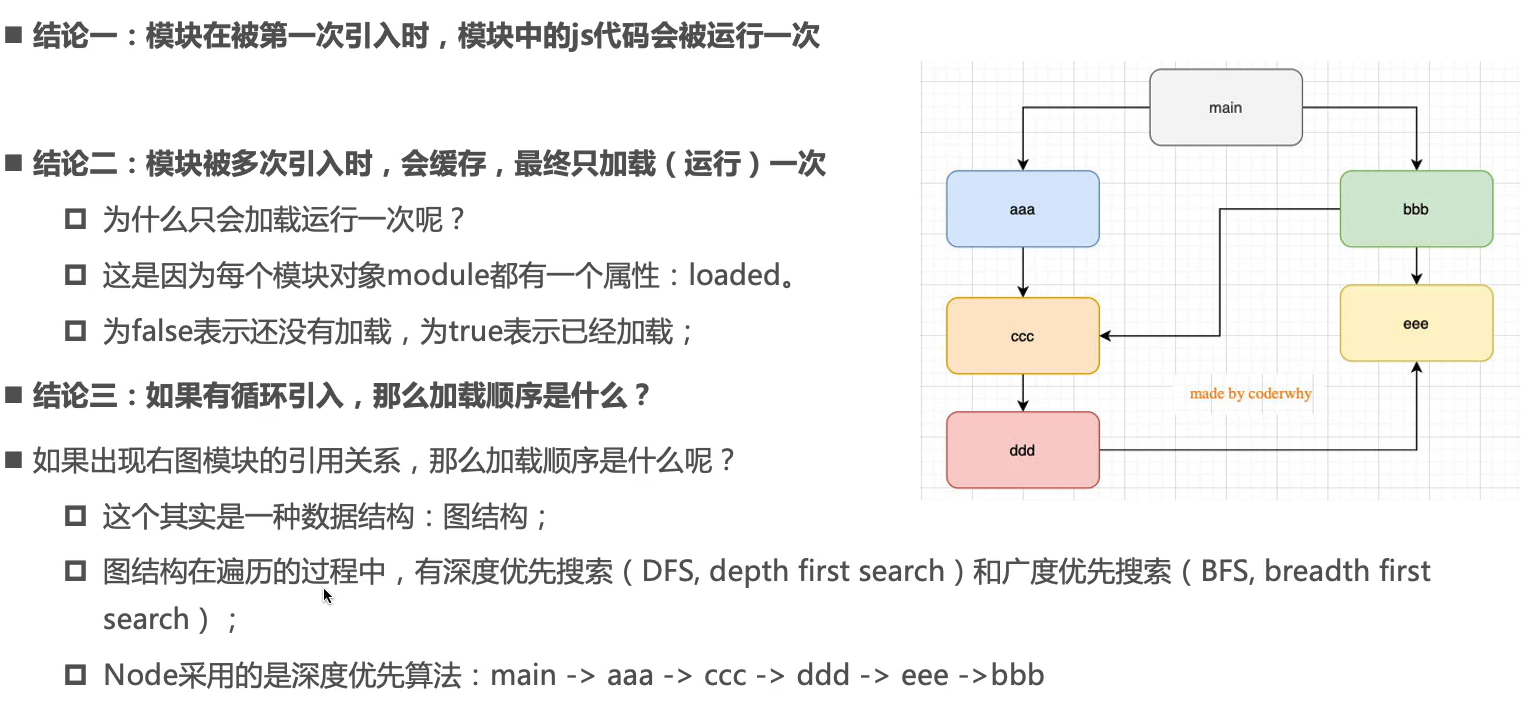
模块的加载过程
CommonJS规范缺点

AMD规范

使用request.js库
1 | - lib |
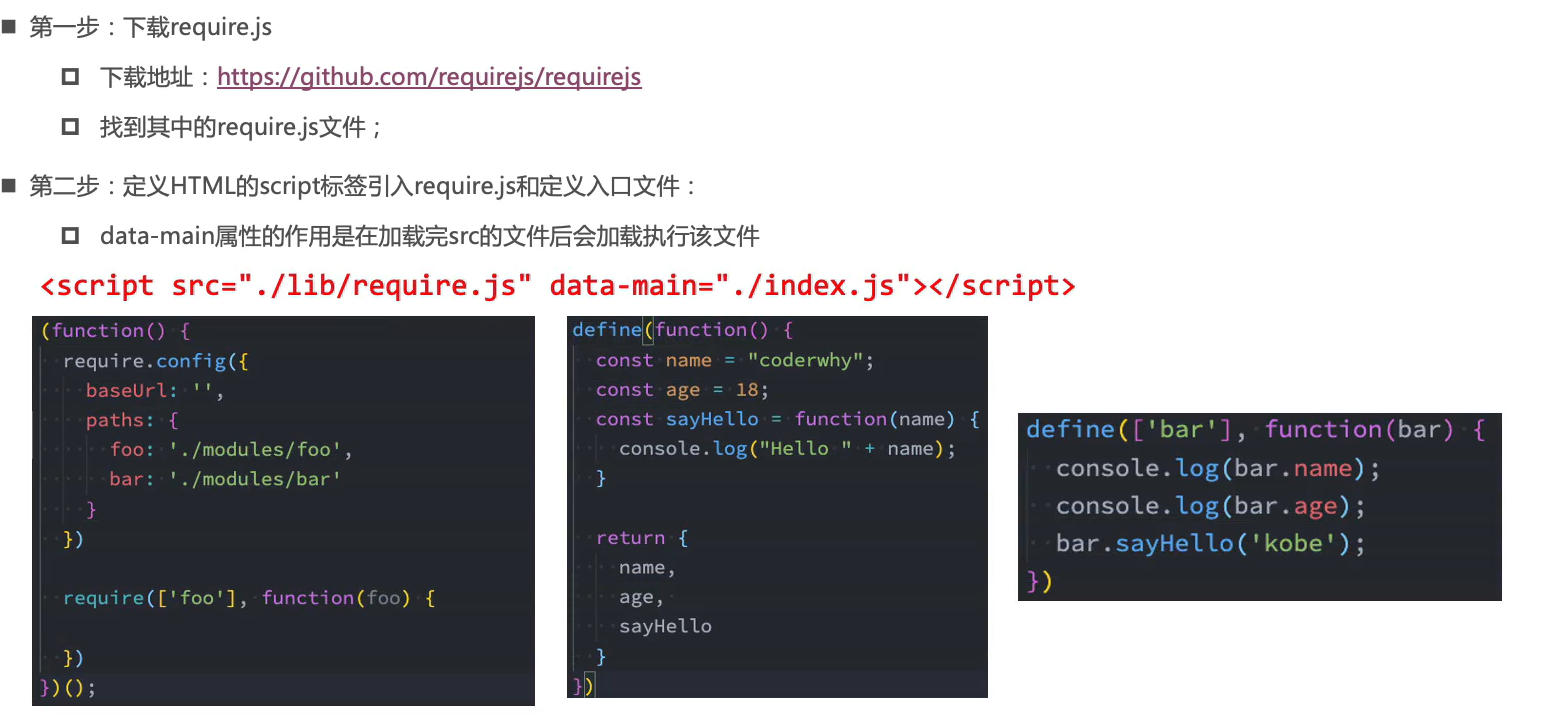
data-main属性放入口文件
index.js中的全局对象
require是在加载的./lib/request.js文件中定义的,可以在函数内部中访问外层作用域在
require.config中配置路径paths,与所有模块一一对应,根据baseUrl找对应路径,paths中配置的路径不加后缀名require用于加载模块,如果function函数体不加任何代码就是纯加载模块,然后就会执行模块里面的代码了define用于定义模块,要求传入函数,函数会被自动执行,要导出的属性放在return后面跟着的对象里。要依赖的模块放在第一个参数的数组中,然后在后面的function参数传入
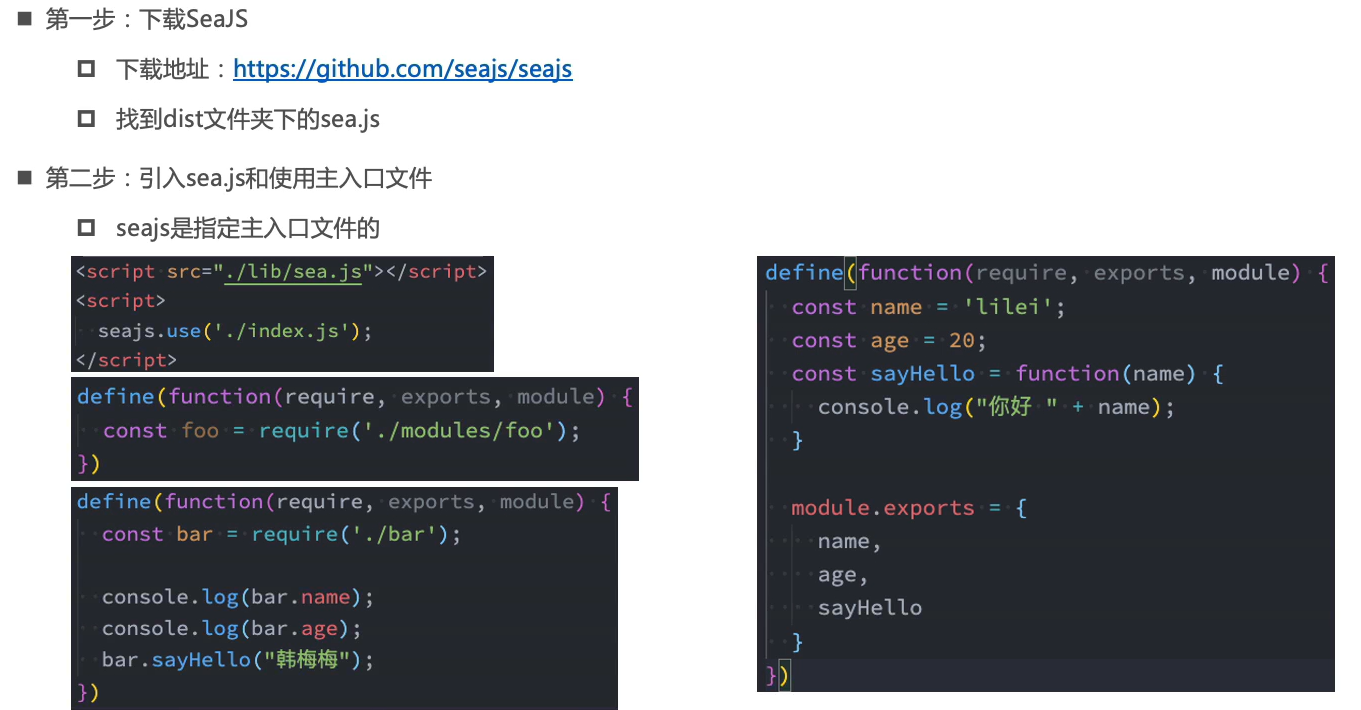
CMD规范

SeaJS的使用
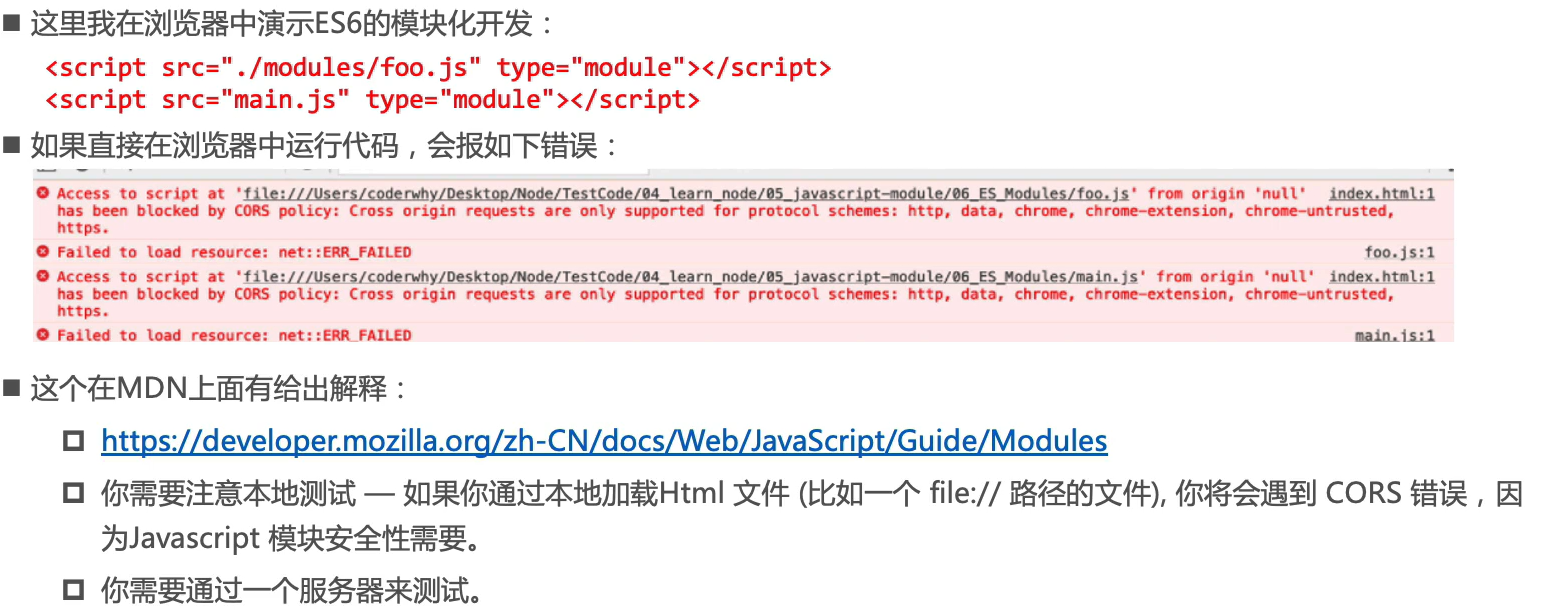
ES Module
采用import和export关键字来实现模块化,在解析的时候需要用到JS引擎来解析关键字
type="module"属性的作用是把加载的文件及其依赖当成模块文件使用
打开HTML文件可能会出现下面的报错(解决方案是在VSCode中用live serve打开)
export关键字
三种用法:
- 在语句声明的前面直接加上export关键字:
export let name = "xxx" - 将所有需要导出的标识符,放到export后面的{}。这里的{}不是ES6的对象字面量的增强写法,也不表示一个对象
- 导出时给标识符起别名:
export {name as myName}
import的用法
三种用法:
import {标识符列表} from '模块',模块那里要加后缀- 导入时给标识符起别名
- 通过
*将模块功能放到一个模块功能对象上:import * as foo from "./foo.js"
export和import结合使用
export {name as myName} from "./foo.js"

default用法

import函数
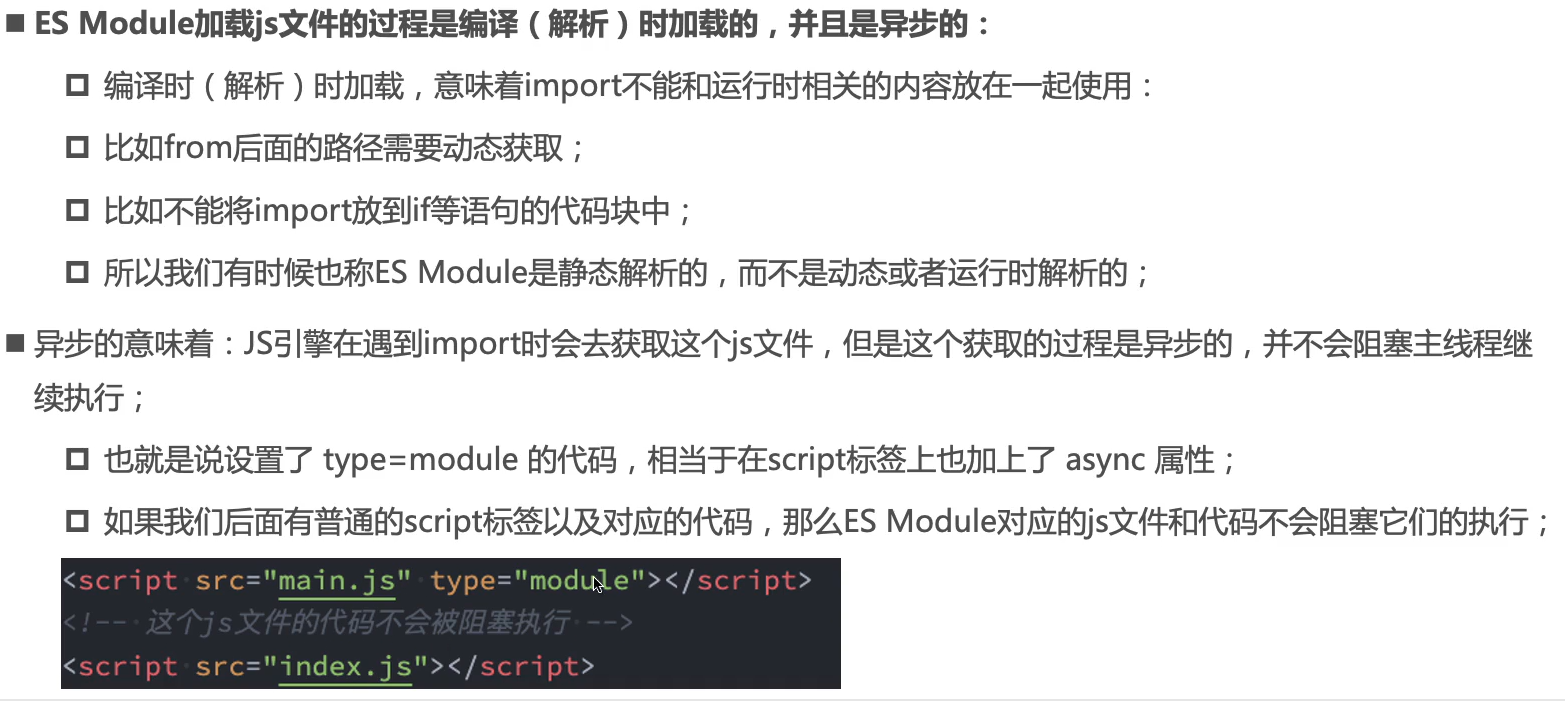
通过import加载一个模块,是不可以将其放在逻辑代码中的。原因是,ES Module在被js引擎解析时,就必须知道它的依赖关系,经过parsing解析,然后生成ATS(抽象语法树),在这个过程中没有运行代码,parsing时已经确定了依赖关系。而原本的import用法如果放在了业务逻辑代码里面相当于把要放在解析阶段的代码放在了运行阶段的代码中。
但是在某些情况下,我们需要实现动态加载模块,所以需要用到import()函数。
require()可以使用是因为其本质是一个函数,如果是在webpack环境下,它既支持es也支持commonJS,可以直接使用require()。
而纯ES Module环境下,需要使用import()。这是一个异步加载,会让浏览器先下载js文件,然后再让js引擎解析,所以有足够的时间加载。import函数返回的是一个promise,可以借此判断是否加载成功
大部分脚手架是基于webpack的,也可以直接使用
import()。这时import函数是交给webpack解析的,把单独引入的js文件单独打包,在进行首屏渲染的时候需要用到哪个就加载哪个js文件
CommonJS的加载过程

ES Module的加载过程

Node对ES Module的支持
1 | // ./modules/bar.js |
报错:不能在模块外面使用import

默认情况下,
.js是CommonJS的模块,而不是ES的模块ES Module中没有自动加文件名后缀,所以在import导入的时候要把后缀加上
如报错信息给出了两种解决方案
- 将后缀
.js修改为.mjs,表示使用的是ES Module - 在package.js中配置
type:module
CommonJS和ES Module交互
通常情况下,CommonJS不能加载ES Module

ESModule是异步加载的,发生在编译时,可能在CommonJS要用到的时候还没有加载好
多数情况下,ES Module可以加载CommonJS

Node常用内置模块
path
在不同的操作系统上的路径是不一样的,为了屏蔽它们之间的差异,在开发中对于路径的操作我们可以使用path模块
拼接路径
path.resolve(basePath, filename)1
2const path = require("path");
const filepath = path.resolve(basePath, filename); //拼接路径,会自动补充相应的分隔符path.join(basePath, filename)两者的区别是:
join方法会直接拼接路径,而resolve方法会判断拼接的路径字符串中,是否有以/或./或../开头的路径,然后进行路径查找。如果有表示一个绝对路径,会返回对应的拼接路径;如果没有,那么回合当前执行文件所在文件夹进行路径拼接
获取路径信息(这里的filename是一个完整的路径)
- 获取文件父文件夹:
path.dirname(filename) - 获取文件名:
path.basename(filename) - 获取后缀名:
path.extname(filename)
- 获取文件父文件夹:
fs
fs是File System的缩写,表示文件系统
借助Node帮我们封装的文件系统,我们可以在任何操作系统上直接操作文件,这也是Node可以开发服务器的一大原因
fs的API大多数提供三种操作方式:
方式一:同步操作文件。代码会被阻塞,不会继续执行
1
const info = fs.statSync(filepath);
方式二:异步回掉函数操作文件。代码不会被阻塞,需要传入回调函数,当获取到结果时,回调函数被执行
1
2
3
4
5
6
7fs.stat(filepath, (err, info) => {
if(err){
...
return
}
...
})可以用
info.isFile()或者info.isDirectory()来判断是文件还是文件夹方式三:异步Promise操作文件。代码不会被阻塞,通过
fs.promises调用方法操作,会返回一个Promise1
fs.promises.stat(filepath).then(info=>{}).catch(err=>{})
文件描述符

1 | fs.open("./abc.txt", (err, fd) => { |
文件的读写
fs.readFile(path[,options],callback):读取文件内容fs.write:传入文件描述符fs.writeFile(file, data[,options], callback):在文件中写入内容
options参数
flag:写入的方式

encoding:字符的编码。如果不填写,返回的结果就是Buffer
文件夹操作
创建文件夹:
fs.mkdir(path[,options],callback)fs.existsSync(dirname):判断文件是否存在读取文件夹中的所有文件:
fs.readdir(dirname, (err, files) => {...}),files包含了dirname文件夹下所有文件名的数组1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 当需要获取dirname下所有子级文件夹的文件名时,可以这样做
// 方法一 利用上面提到的fs.stat
// 方法二 fs.readdir中额外传入withFileTypes参数,此时的files是对象数组
function getFiles(dirname) {
fs.readdir(dirname, {withFileTypes: true}, (err, files) => {
for(let file of files) {
if (file.isDirectory()) {
const filepath = path.resolve(dirname, file.name);
getFiles(filepath);
}else{
console.log(file.name);
}
}
})
}
getFiles(dirname)重命名:
fs.rename(oldPath, newPath, callback)文件夹的复制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32const fs = require('fs');
const path = require('path');
const srcDir = '/Code/Test';
const destDir = '/Code/学习代码/temp';
let i = 0;
while(i < 2){
i++;
const num = 'dir' + (i + '').padStart(2,0);
const srcPath = path.resolve(srcDir, num);
const destPath = path.resolve(destDir, num);
if(fs.existsSync(destPath)) continue;
fs.mkdir(destPath, (err) => {
if (!err) {
console.log(`文件${destPath}创建成功开始拷贝`);
}else{
console.log(err);
}
//遍历目录下所有文件
const srcFiles = fs.readdirSync(srcPath);
for(const file of srcFiles){
if (file.endsWith('.txt')) {
const srcFile = path.resolve(srcPath, file);
const destFile = path.resolve(destPath, file);
fs.copyFileSync(srcFile, destFile);
console.log(file, "拷贝成功");
}
}
})
}比较需要注意的点是一开始
srcDir和destDir别写错了
关于路径的补充说明
在项目中的任何一个地方,使用的相对路径都是相对于process.cwd,对应的是启动项目所在的文件夹
举例说明,code文件夹下有项目demo1,demo1下有keys文件夹,如果进入了demo1路径启动项目,那么相对路径为./keys/...的时候可以正常运行。如果是在code文件夹下启动项目(nodemon demo1/index.js),那么demo1项目中的相对路径要改成./demo1/keys/...
或者直接在项目中使用path.resolve(__dirname,)拿到当前所在目录,然后再作路径拼接
events

基本用法:
1 | const EventEmitter = require("events"); //导入的是一个类 |
EventEmitter的实例有一些属性,可以记录一些信息,用到了再查API文档吧
补充一些别的方法:

包管理工具
npm
npm install原理
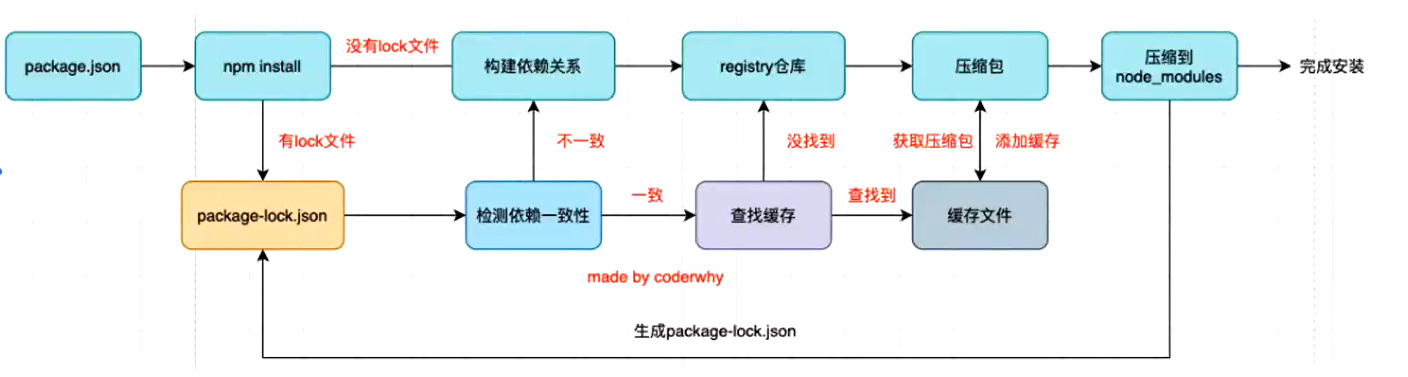

yarn
是为了弥补npm一些缺陷而出现的。早期的npm存在安装依赖速度很慢、版本以来混乱等一系列的问题
cnpm

npx
开发脚手架工具
指令 commander.js/Readme_zh-CN.md at master · tj/commander.js · GitHub
其他参考网站:
创建项目
定义入口文件:创建
index.js项目初始化:
npm init -y,对包进行管理 -y 的含义在init的时候省去了敲回车的步骤,生成的默认的package.json。package.json文件中就会把index.js定义为入口文件#!:shebang。在其后可以配置一个环境,会根据配置的环境执行当前的文件。在index.js文件的顶部\#!/usr/bin/env node——在当前电脑环境找node指令。然后交给node来执行npm link:将bin与真正的环境变量连接,然后将mycli作为终端命令配置到环境变量里,这样敲mycli才会生效。同时生成package-lock.json版本
program.version(require("./package.json").version)在使用
-V或--version的时候会在控制台打印版本号options 选项
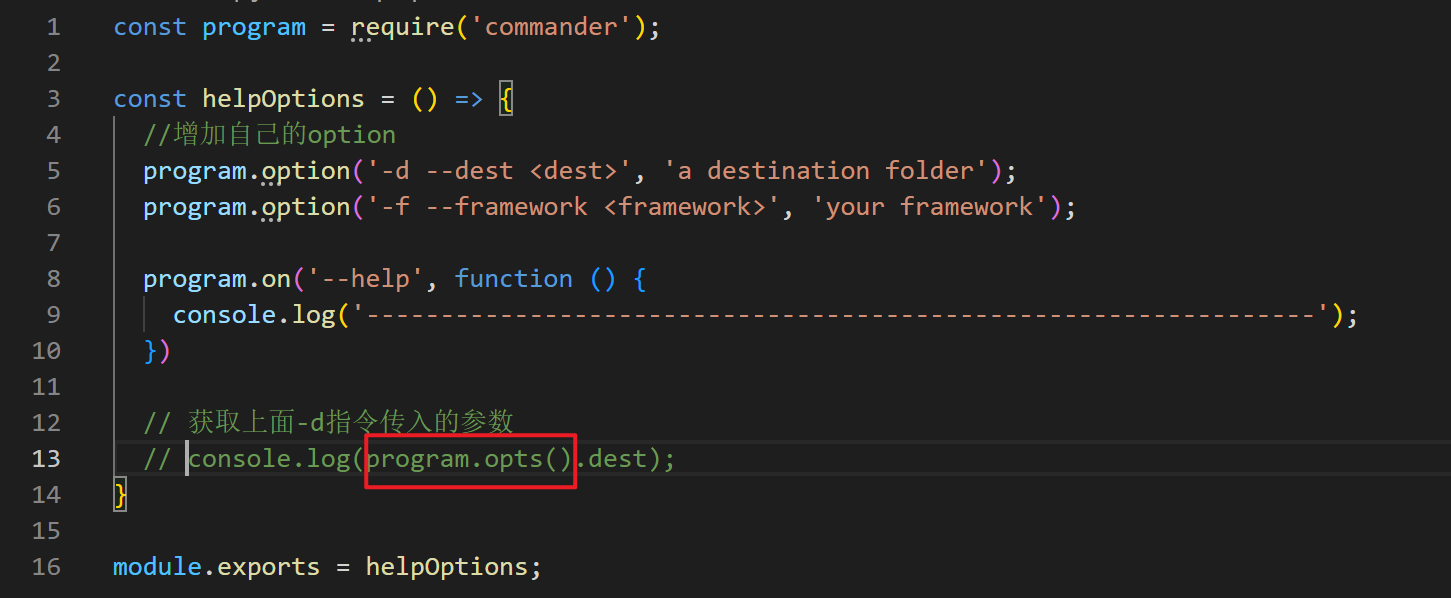
1
2
3
4// index.js
helpOptions();
program.parse(process.argv);
//console.log(program.opts().dest) //{1}!?
index.js文件没有添加下面的createCommands之后,直接运行像是mycli、mycli -d sss都可以执行{1}然后把相应结果打印出来。但是index.js文件添加了createCommands之后,直接运行mycli执行的是不再是(?)纯运行index.js,parse后面如果再接着要console.log都没有反应。(无论是不是打印program.opts())配置命令——create
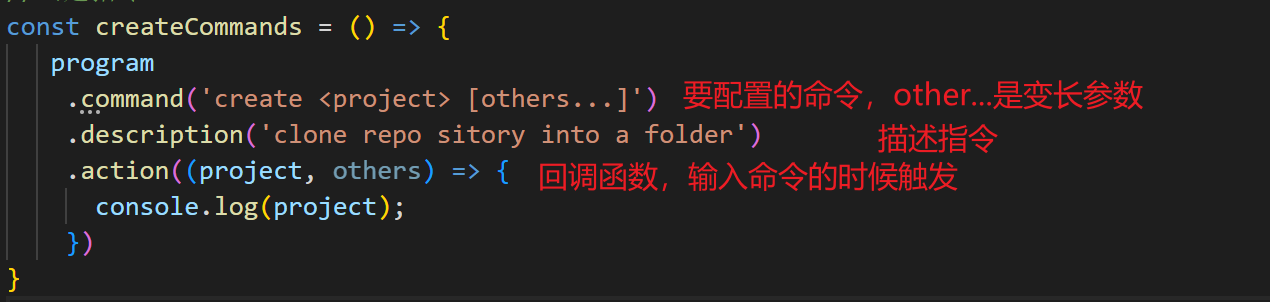
在
mycli create demo的时候,知道创建的新项目是demo,然后去github把代码clone到demo文件夹中,从而实现创建项目。为了配置方便,封装
actions,方便维护代码,.action(createProjectAction)actions执行的内容包括:clone项目 -> 执行npm install -> 运行npm run serve -> 打开浏览器
(1) clone项目用到
download-git-repo,导入这个库得到的是一个函数(2) 执行npm install就是让clone下来的项目能供自动生成
node_modules,这里封装一个terminl.js,用于执行终端命令的文件,用到child_process模块中的spawn,开启新进程(平时的npm install那些也是开启新的进程)(3) 防止堵塞,不要用await。因为封装的
commandSpawn需要结束进程才会调用resolve(),而运行npm run serve的时候需要ctrl c才可以结束进行。此时就是异步调用,但是不会阻塞(4) 用到第三方库
openvuecli本身没有做自动打开浏览器的操作,是webpack做的
配置命令——appcpn、addpage、addstore…
addcpn:
整体逻辑:根据组件模板生成
.vue文件,前端用的最多的模板是.ejs步骤:用对应的
ejs模板 -> 编译ejs模板,得到字符串result -> 将result写入到.vue-> 放到对应文件中(1) lib/templates/下创建
.ejs模板,使用ejs.renderFile方法对模板进行编译1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// lib/utils/utils.js
const ejs = require('ejs');
const path = require('path');
const compile = (templateName, data) => {
// ejs.renderFile方法渲染某个文件,传入路径
const templatePosition = `../templates/${templateName}`;
const templatePath = path.join(__dirname, templatePosition); // __dirname是D:\Code\学习代码\007-深入Node.js技术栈(完结)\code\work\LEARN_CLI\lib\utils
// 传入的是{data}而不是{name:xx}的原因是模板文件中是用data.name获取数据的
// 借助promise把结果return出去
return new Promise((resolve, reject) => {
ejs.renderFile(templatePath, { data }, {}, (err, result) => {
if (err) {
console.log(err);
reject(err);
return;
}
resolve(result);
})
})
}
module.exports = {
compile
}
// lib/core.actions.js addComponentAction
const result = await compile("vue-component.ejs", {name, lowerName: name.toLowerCase()});(2) 编译
ejs模板在utils.js中封装好
compile方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17const compile = (templateName, data) => {
// ejs.renderFile方法渲染某个文件,传入路径
const templatePosition = `../templates/${templateName}`;
const templatePath = path.join(__dirname, templatePosition); // __dirname是D:\Code\学习代码\007-深入Node.js技术栈(完结)\code\work\LEARN_CLI\lib\utils
// 传入的是{data}而不是{name:xx}的原因是模板文件中是用data.name获取数据的
// 借助promise把结果return出去
return new Promise((resolve, reject) => {
ejs.renderFile(templatePath, { data }, {}, (err, result) => {
if (err) {
console.log(err);
reject(err);
return;
}
resolve(result);
})
})
}(3) 写入文件
关于
addstore和addpage,需要考虑到一个文件路径的问题。一个是将创建的新文件单独放在一个文件夹里,然后在放到指定的路径下,另一个是要判断指定的路径是否存在。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// utils/utils.js 问题二
const createDirSync = (pathName) => {
if (fs.existsSync(pathName)) {
// 当前路径存在
return true;
}else{
//判断父路径是否存在
if (createDirSync(path.dirname(pathName))){
fs.mkdirSync(pathName);
return true;
}
}
}
// actions.js
// 添加组件和路由
const addPageAndRoute = async (name, dest) => {
// 1. 编译ejs模板 result
const data = { name, lowerName: name.toLowerCase() }
const pageResult = await compile("vue-component.ejs", data);
const routeResult = await compile("vue-router.ejs", data);
// 2. 写入文件的操作
const targetDest = path.resolve(dest, name.toLowerCase()); //{问题一}
if (createDirSync(targetDest)) {
const targetPagePath = path.resolve(targetDest, `${name}.vue`);
const targetRoutePath = path.resolve(targetDest, 'router.js');
writeToFile(targetPagePath, pageResult)
writeToFile(targetRoutePath, routeResult)
}
}最后写入文件使用
fs.promises.writeFile(path, content);}上传脚手架到npm.registry
在上传前对
package.json进行修改,补充keywords,author,license(开源协议),homepage,repository等信息npm上注册账号 ->npm login->npm publish
Buffer的使用
计算机中所有的内容最终都会使用二进制来表示
JavaScript一般只会直接处理一些直观的数据,比如字符串。其实也可以处理图片、音频等,但是很少。(直接处理二进制数据有一点无能为力。
事实上在网页端,图片我们一直是交给浏览器来处理的。JavaScript或HTML只是负责告诉浏览器一个图片的地址。浏览器负责获取这个图片,并且最终将图片渲染出来。

Buffer和二进制
只要在Node当中,处理二进制最好的是使用Buffer

Buffer相当于是一个字节的数组,数组中的每一项是一个字节的大小
Buffer和字符串
编码:可以通过new Buffer(string)或Buffer.from(string),比较建议后面一种方式。创建Buffer并进行填充,内部会将字符串每个字符做编码然后放到Buffer中。一个英文占据一个字节,一个中文占据三个字节(默认是utf8编码,如果是utf16编码Buffer.from(string,'utf16le')就是一个中文占据两个字节)
解码:buffer.toString(),解码的时候是以utf8解码的,如果是在编码的时候指定了编码方式,那么解码的时候也要进行指定,例如buffer.toString('utf16le')
创建Buffer的其他方式
Buffer.alloc(size[, fill[, encoding]]), 分配内存的形式进行创建。创建的buffer默认每一个字节都是00。如果要对buffer进行修改可以使用buffer[index]的方式进行赋值。对于buffer[0] = 88的类型,buffer会将88转换成十六进制再保存,于buffer[0] = 0x88的则会直接保存88,因为0x开头表示十六进制
Buffer和文件操作
文本文件操作
使用fs.readFile()方法读取文件内容的时候,本质上读取到的都是二进制的内容,如果没有给fs.readFile()传递编码,那么返回的就是buffer。而fs.readFile("path, {encoding: 'utf-8'}, callback}),会帮我们按照utf8转化
图片文件操作
无法传入编码,直接获取的就是buffer。Node中的sharp库可以读取图片或者传入图片的buffer对其进行处理

Buffer的创建过程
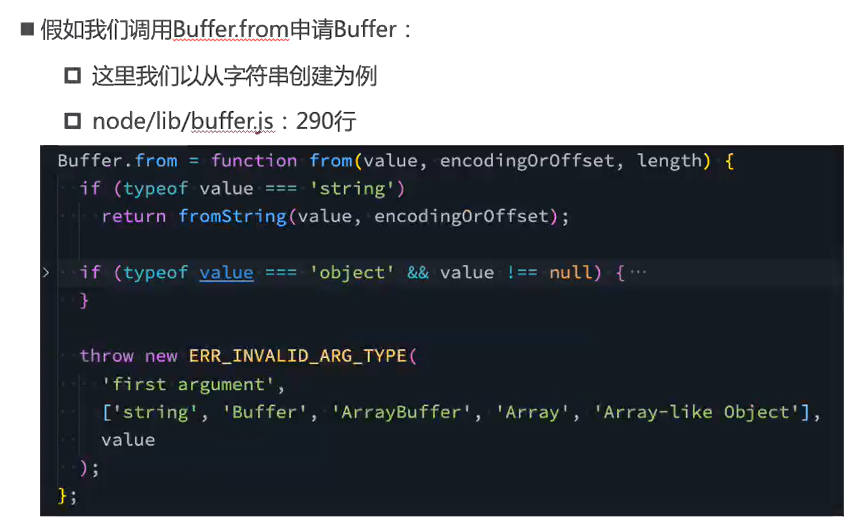
事实上在创建Buffer的时候,不会频繁的向操作系统申请内存,它会先默认申请一个8*1024个字节大小的内存,也就是8kb,相关源码:
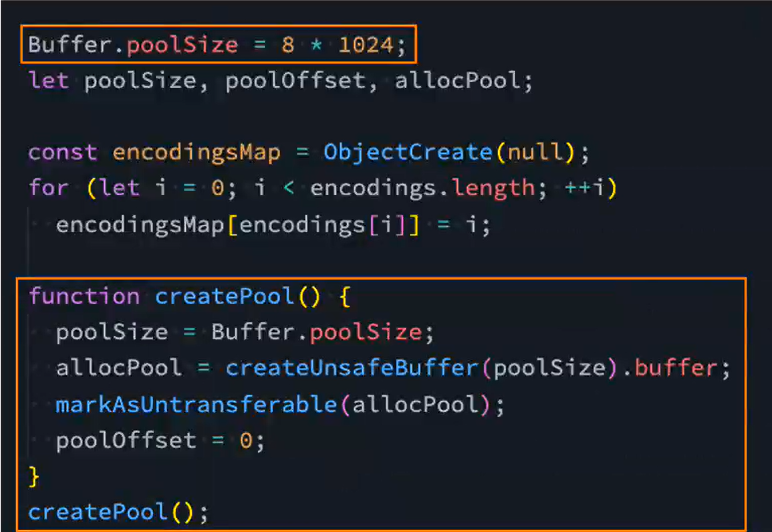
Buffer.from()源码:
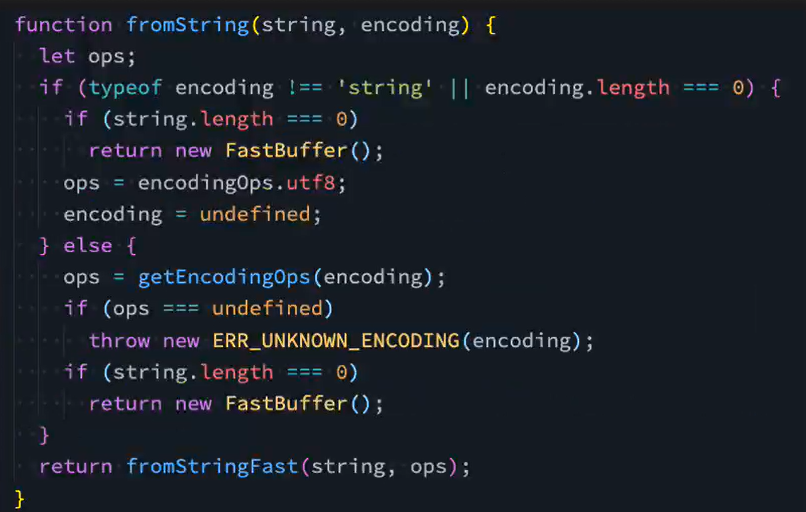
fromString源码:
fromStringFast:

事件循环和异步IO
事件循环
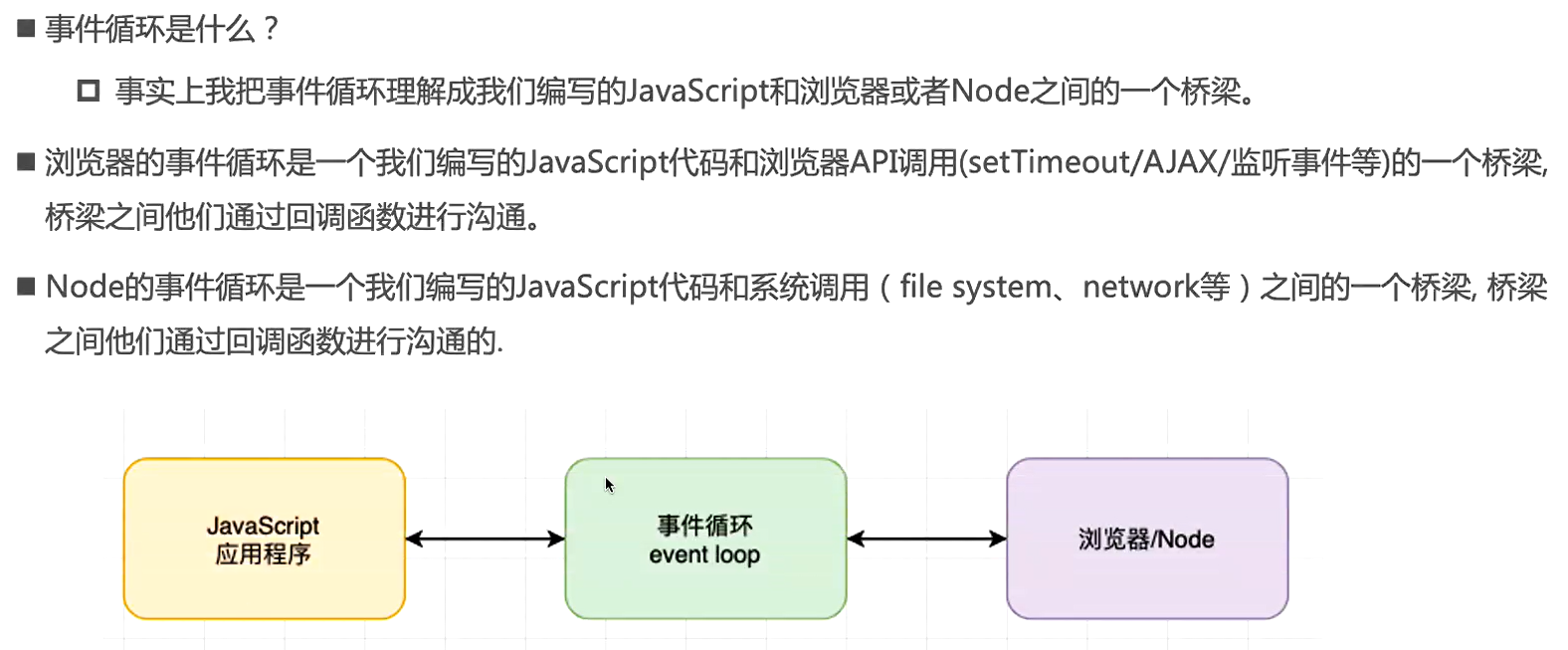
进程和线程
概念
线程和进程是操作系统中的两个概念:
- 进程(process):计算机已经运行的程序。我们可以认为,启动一个应用程序,就会默认启动一个进程(也可能是多个进程,浏览器就是多进程的)
- 线程(thread):操作系统能够运行运算调度的最小单位。每一个进程中,都会启动一个线程用来执行程序中的代码,这个线程被称为主线程
- 所以我们也可以说进程是线程的容器,进程至少会开启一个线程,默认开启的线程就是主线程
- 或者把操作系统、进程、线程,看成是工厂、车间、车间工人的关系
多进程多线程开发
操作系统可以同时让多个进程同时工作的原因:CPU的运算速度非常快,它可以快速的在多个进程之间迅速切换。当我们的进程中的线程获取到时间片时,就可以快速执行我们的代码,而用户是感受不到这种快速的切换的。
浏览器和JavaScript
JavaScript是单线程的,它有自己的容器进程:浏览器或者Node
目前多数浏览器时多进程的(比如Chrome),每打开一个tab页面就会开启一个新的进程,这是为了防止一个页面卡死而造成所有页面无法响应,整个浏览器需要强制退出。只要关闭页面就可以销毁该进程
每个进程中又有很多线程,其中包括执行JS代码的进程。
但是JS的代码执行是在一个单独的线程中执行的(只有一条执行路径),这就意味着JS的代码在同一时刻只能做一件事,如果这件事时非常耗时的,就意味着当前线程会被阻塞
JavaScript执行过程

添加异步操作之后:
浏览器的事件循环

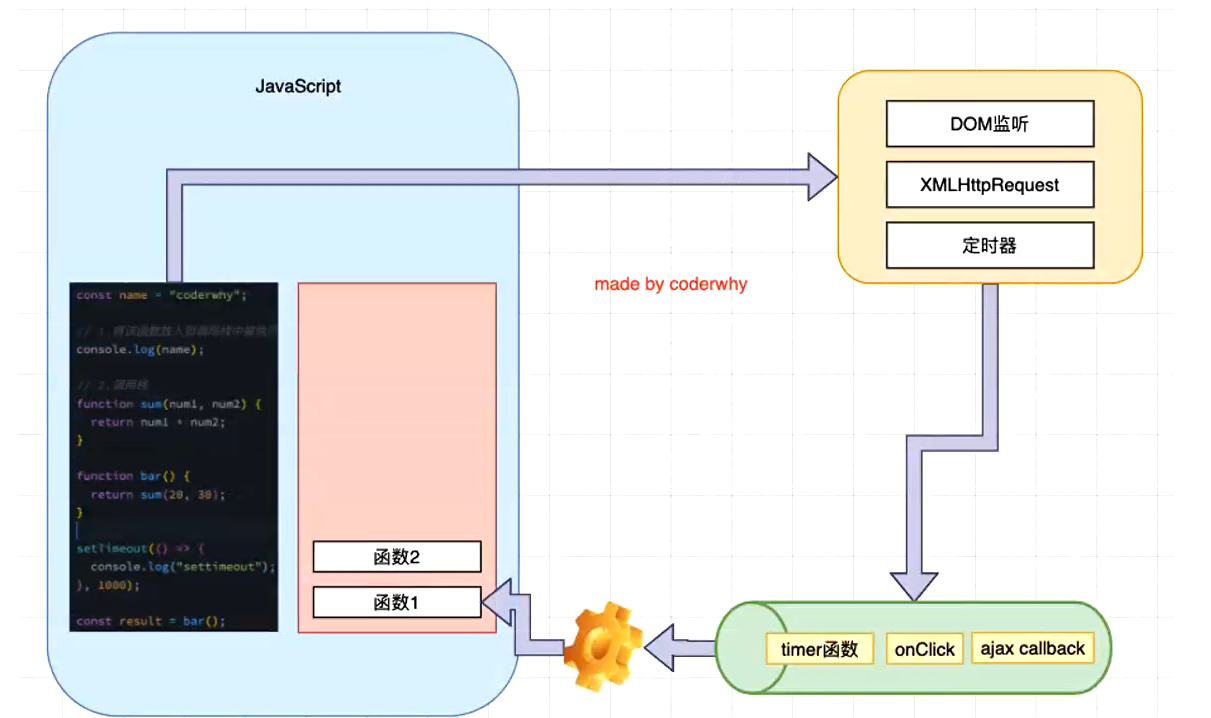
调用setTimeout的时候不会发生阻塞,同时浏览器把回调函数timer函数保存起来,等到时间之后就把他取出来,放入事件队列中,事件循环一旦发现队列中有需要执行的东西(按照顺序执行),就会将其放入到调用栈中执行
宏任务和微任务

关于async/await:async、await是Promise的一个语法糖。我们可以将await后面执行的代码看作是包裹在(resolve, reject) => {...}中的代码,await的下一条语句,可以看作是then(res=>{...})中的代码
实例
例一
1 | setTimeout(function () { |
例二
1 | async function async1(){ |
Node的事件循环
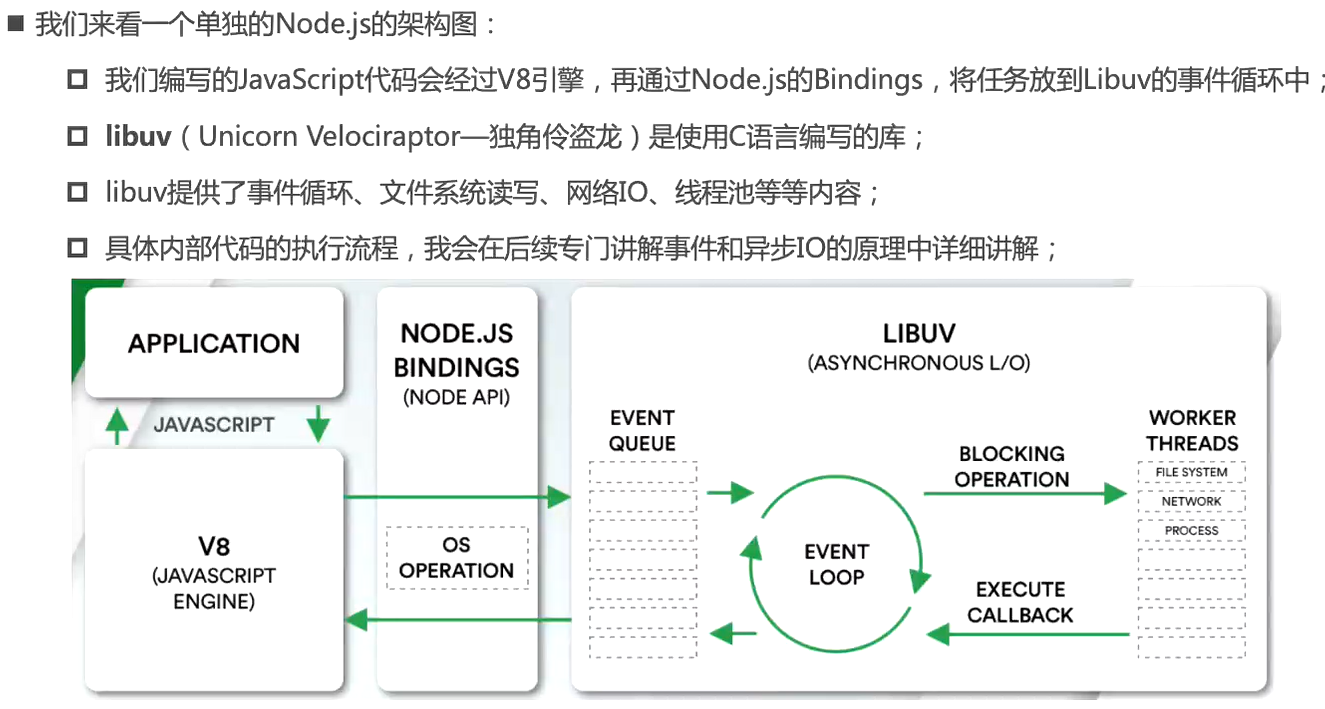
Node的架构分析
浏览器中的EventLoop是根据HTML5定义的规范来实现的,不同的浏览器可能有不同的实现,而Node中是由libuv实现的
libuv是一个多平台的专注于异步IO的库,它最初是为Node开发的,但是现在也被使用到Luvit、Julia、pyuv等其他地方
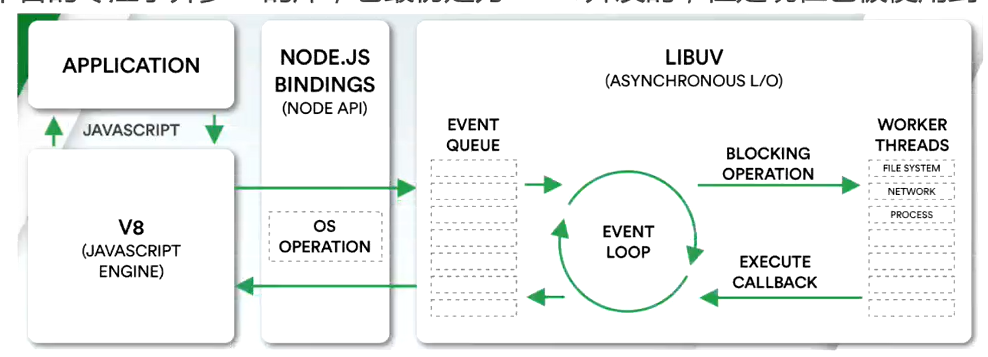
libuv中主要维护了一个EventLoop和worker threads(线程池)。EventLoop负责调用系统的一些其他操作:文件的IO、Network、child-processes等
阻塞IO和非阻塞IO

非阻塞IO的缺点
为了知道是否读取到了完整数据,我们需要频繁的去确定读取的数据是否完整的。这个过程称为“轮询操作”
libuv提供了一个线程池(Thread Pool),负责所有相关的操作,并且通过轮询或者其他方式等待结果(取出线程完成我们需要的操作)当获取到结果时,就可以将对应的会带放到事件循环(某一个事件队列中)。事件循环负责接管后续的回调工作,(把函数放入调入栈中)告诉JS应用程序执行对应的回调函数。
阻塞和非阻塞,同步和异步的区别

(阻塞和非阻塞一般是对于系统调用来说的
Node事件循环的阶段

其中,在轮询阶段检测IO阶段停留时间最长。因为希望IO的回调尽可能早的响应,所以会作停留
Node的宏任务和微任务
早期的Node执行机制与浏览器不一样,在比较新的Node版本中与浏览器的统一了

一次tick需要执行的:(执行顺序也如下)

io相关队列是要进行系统调用然后告诉我们是否读完了,不能确定时间,所以不好判断会出现在哪一次的tick中
执行顺序
1 | setTimeout(() => { |
执行上面的示例代码结果可能有两种。
在Node源码中有一个uv_next_timeout函数,计算距离当前事件节点最小的计时器,如果为空,即没有计时器,就return -1,此时处于一个阻塞的状态 。如果计时器的事件小于当前loop的开始时间,那么返回0,继续执行后续阶段,并且开启下一次tick。如果不大于loop的开始时间,那么会返回时间差。这个函数决定了poll阶段要不要阻塞在这里。阻塞在这里的目的是当有异步IO被处理时,尽可能让代码被执行。
在main script执行完之后,会开启事件循环初始化。

Stream
流是字节的一种表现形式和抽象概念
虽然可以通过readFile或者writeFile读写文件,但是都是一次性读取/写入所有内容到程序(内存)种,流可以让我们更精细的进行读写操作,比如确定读取的起始位置还有一次性读取字节的长度,默认是64kb
文件读写的Stream

Readable
fs.createReadStream(),返回ReadStream,继承自stream.Readable,stream.Readable继承自Stream,实现了接口NodeJS.ReadableStream,这个接口本身继承自EventEmitter
1 | const fs = require('fs'); |
其中每个buffer内容都是间隔一秒才打印下一个的
Writable
?学习代码用的是16.14.1版本,api文档中
createWriteStream方法中options参数没有flags,所有write操作都是把传入的内容添加文件末尾(所以start也无效了)。即使切换了15.14.0版本(api文档有flags),也不能达到预期效果。PS:两个版本下,VScode都没有提示
createWriteStream方法中的options参数有flags
1 | const writer = fs.createWriteStream("./foo.txt", { |
在写入内容的过程中,文件一直是没有关闭的。在开发的过程中,一般不会直接调用writer.close()来关闭文件,而是调用writer.end()方法。end方法可以传参,一方面会把传入的参数写入文件,另一方面会调用close
pipe方法
实现读取了一个文件的内容之后拷贝到另一个文件中
reader.piper(writer),将读取到的流通过管道输入到另一个流
Http模块
最主要目的是帮助开发Web服务器
Web服务器
概念:当应用程序(客户端)需要某一个资源时,可以向一台服务器,通过Http请求获取到这个资源。提供资源的就是Web服务器
目前开源的Web服务器有:Nginx、Apache(静态)、Apache Tomcat(静态、动态)、Node.js
创建服务器
下面两种方法本质一样
http.createServer([options][, requestListener])requestListener监听器:监听客户端向服务器发送请求,传入一个回调函数
1
2
3const server = http.createServer((req, res) => {
res.end("hello server")
;})req:
typeof http.IncomingMessageNode源码中追溯res参数的继承链,本质上是stream.Readable
没找到为啥不叫ServerRequest,虽然好像也有这个说法
res:
typeof http.ServerResponseNode源码中追溯res参数的继承链,本质上是stream.Writable
new http.Server(requestListener)
request对象
围绕上述requestListener回调函数的第一个参数
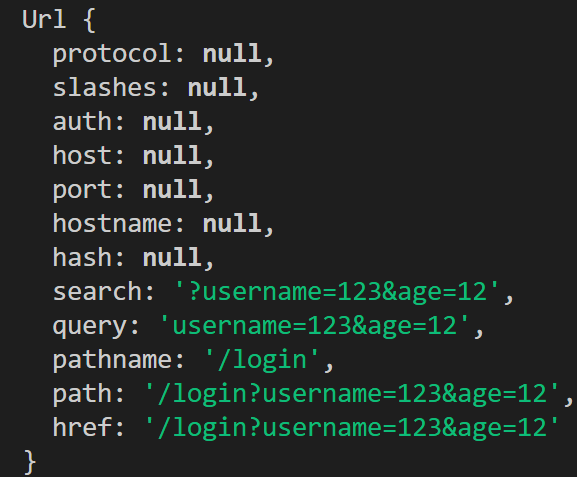
url属性:
req.url返回的是形如下图的String类型数据
提取数据
通过内置模块
url的url.parse(req.url)进行解析,将URL string解析为URL object,然后把pathname和query属性提出来就好了处理
query属性通过内置模块
querystring的qs.parse(query)进行解析,返回的一个对象,解构提取所需数据处理body中的数据
body中的数据是通过流的方式写入的,且查找
http.IncomingMessage的原型链可以找到EventEmitter,故可以使用on方法监听,req.on('data',(data)=>{})此时获取到的data是buffer格式,可以通过
req.setEncoding('utf-8')或者data.toString()转换成字符串格式(如果是音频等数据,则转成二进制req.setEncoding('binary'))
headers属性:



response对象
围绕上述requestListener回调函数的第二个参数
如果我们希望给客户端响应结果数据,可以使用write方法和end方法直接写出数据,后者再写出后会关闭流
只可以通过
res.end()结束,不能用res.close(),只有server有close方法,
几种常用方法:
res.statusCode(statusCode):设置状态码res.setHeader(name,value):设置响应的头部res.writeHead(statusCode[, statusMessage][, headers]):设置状态码和响应的头部,headers是Object类型
启动服务器
Server通过listren方法启动服务器
工具nodemon:监听文件是否发生改变,若改变则重启服务器。安装成功后使用方法就是
nodemon 文件名,这个语法跟node运行文件一样

http请求(原生)
Nodejs中也可以用axios
发送GET请求
使用http.get(url[, options][, callback]),其中callback的格式是(res: http.IncomingMessage) => void) ,注意到这里同样将参数命名为res但为http.IncomingMessage类,所以要通过on来取它的数据,可以获取到创建服务器的代码块中通过res.write()和res.end()写入的数据
同样是
http.IncomingMessage,createServer的requestListener第一个参数req可以通过req.url,req.method、req.headers来取到相应数据。但是这里的res.url为空,res.method为null在官方文档中,对于
url和method属性有一个一样的解释:Only valid for request obtained from http.Server。应该就是这个缘故,毕竟createServer返回的是就是一个http.Server类型
1 | http.get("http://localhost:8888/test?username=1111", (res) => { |
发送POST请求
http.request()方法,参数详情见文档,常见的使用如下:
1 | const req = http.request("http://localhost:8888/",{ |
对于http.request()方法的使用,必须在最后调用req.end()方法,标记请求配置已经完成,否则会堵塞。调用end方法的时候才是将请求发送出去
文件上传
==知识补充==
| 请求体携带的数据类型 | 对应的content-type | 使用场景 | 描述 |
|---|---|---|---|
| form-data | multipart/form-data; boundary…(boundary表示分割符) | 表单提交 文件上传 | 服务器解析很麻烦,很少手动解析,在express中用multer处理 |
| x-www-form-urlencoded | application/x-www-form-urlencoded | ||
| row | application/json(选择JSON的时候) | 使用最多,比如平时的登录场景 |
两种错误的写法
1 | const server = http.createServer((req,res) => { |
这两种方式本质上是一样的,往文件写入的除了图片本身的数据还有一些别的数据,所以解析会失败
正确写法
1 | // 完整代码 |
首先,由于我们是在操作图片,所以要标记编码为二进制,req.setEncoding("binary");
body初始值如下:
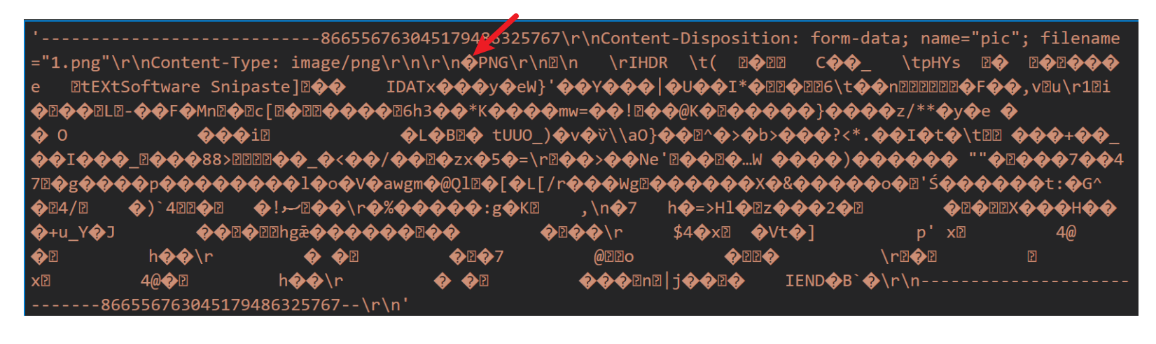
箭头所指的前面是body基本信息,箭头所指PNG后面及最末尾的分隔符中间的数据的才是图片信息
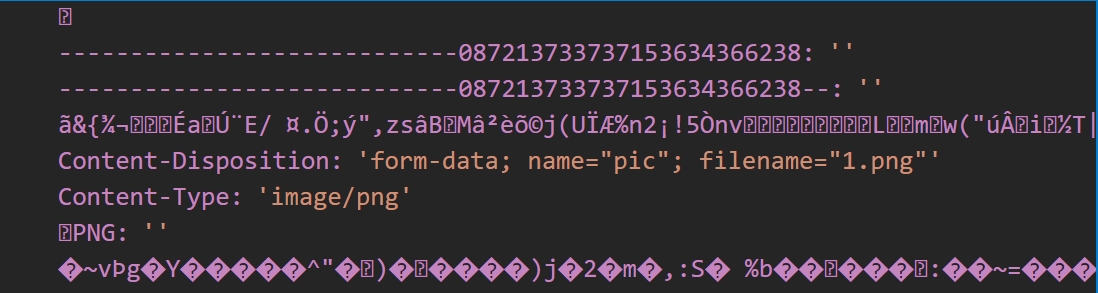
故而整体思路是先找到image/png的位置,然后把前面的部分先切割掉
使用到querystring模块的querystring.parse(str[, sep[, eq[, options]]])方法,其中关于sep和eq的官方解析:

切割后的payload如下:
Express框架
Express安装
方式一
方式一:通过express提供的脚手架,直接创建一个应用的骨架,安装express-generator
- npm install -g express-generator
- express express-demo
- npm install
- node bin/www 启动项目
方式二
从零搭建自己的express应用结构
- 创建一个文件夹
- npm init -y
- npm install express
Express的基本使用
在express项目中创建js脚本,同样使用node来运行文件
1 | // 导入express |

对于路径参数的传递,路径可以写作login/:userId,然后通过req.params.userId获取
中间件
Express是一个路由和中间件的Web框架,它本身的功能非常少。Express应用程序本质上是一系列中间件函数的调用
中间件的本质是传递给express的一个回调函数,这个回调函数接收三个参数,分别是请求对象(request对象)、响应对象(response对象)、next函数(在express中定义的用于执行下一个中间件的函数)
中间件中可以执行的任务如下:
- 执行任何代码
- 更改请求和响应对象
- 结束请求-响应周期(返回数据)(调用
res.end())- 如果当前中间件功能没有结束请求-响应周期,则必须调用
next()将控制权传递给下一个中间件功能,否则,请求将被挂起
- 如果当前中间件功能没有结束请求-响应周期,则必须调用
- 调用栈中的下一个中间件
- 所有中间件都是放到一个stack中的,调用
next()本质是取出并调用下一个中间件
- 所有中间件都是放到一个stack中的,调用
应用中间件
自己编写
将中间件应用到应用程序中主要有两种方式:app/router.use和app/router.methods,其中methods指的是常用的请求方式。后者的本质是前者的特殊情况
app.use()的使用使用
app.use([path], function)方法,传入路径参数和回调方法注册中间件。path为路径参数;function是一个回调函数,格式为(req, res, next) => {...},这里的
req和res类型分别为IncomingMessage和ServerResponse,在使用过程中配合前面学到的知识当不传入
path参数时,可以响应所有的请求,也就是发送任意请求都会注册当前中间件。当需要注册多个中间件时,发送的请求总是会寻找所有匹配的中间件,但是只有第一个注册的中间件会响应请求,如果需要接下来的中间件也可以响应,必须调用
next()。next()会去寻找下一个能匹配上的中间件next()与res.end()的起效与否与它们的相对位置没有必然关系,后者只是表示结束了当前中间件的请求-响应周期,并不妨碍服务器next()执行下一个中间件开发过程中,一般把
res.end()放在最后一个中间件中。前面的话要写也只能写res.write()当传入了
path参数,则可以根据路径匹配中间件app.methods()的使用使用
app.methods()必须同时传入路径参数和回调方法,其余解析同上app.use()和spp.methods()都可以同时传入多个回调函数连续注册中间件,不要忘记加上next()
body解析
手动
当发送POST请求的时候我们可以通过以下方式拿到body数据。
思路:以传递数据格式是JSON为例。在app.use()中手动判断请求头携带的数据是json,通过req.on()监听数据读取的过程,然后把读到的数据data通过JSON变换后赋值给req.body,然后可以在下面精准匹配的中间件中通过req.body获取到请求体的数据
数据比较多的时候要先把data拼接
1 | app.use((req, res, next) => { |
如果数据类型为
x-www-form-urlencoded,此时content-type的值是application/x-www-form-urlencoded,需要另外手动判断
express提供
可以使用第三方库body-parser
express3.x——内置到express框架
express4.x——分离出去
express4.16.x——(类似功能)内置成函数
使用方法:
解析JSON
app.use(express.json()),express.json()返回的中间件实现的就是上面的关键代码部分。解析
x-www-form-urlencoded使用
app.use(express.urlencoded({ extended: true }));extended取值 描述 true 对urlencoded进行解析时使用第三方库:qs false 对urlencoded进行解析时使用node内置的:querystring ==两个库的区别==
解析
form-data不要忘记前端form表单标签需要添加对应属性:
enctype="multipart/form-data"上传普通数据:
借助第三方库
multer,这个库也是express开发的,但是没有集成到框架里1
2const multer = require('multer'); //导入的也是一个函数
const upload = multer(); //返回的是一个multer的Multer对象此时在对应的中间件中同样通过
req.body可以获取到请求体数据,同时添加upload.any()这个中间件,否则req.body值为{}
上传文件:
在
app.post()传入的参数中,除了对应的接口路径和一个告知用户文件上传成功的回调函数(中间件),还添加一个中间件用来获取上传的文件并进行保存。如果上传单个文件,那么调用upload.singer(),如果上传多个文件则调用upload.array(),传入参数均为所需处理的数据的key注意,默认情况下,上传的文件没有后缀名,需要手动添加。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25const path = require('path');
const multer = require('multer'); //导入的也是一个函数
const storage = multer.diskStorage({
destination: (req, file, cb) => {
cb(null, './uploads')
},
filename: (req, file, cb) => {
//指定文件的名字为 时间戳+原文件名的后缀名
cb(null, Date.now() + path.extname(file.originalname))
},
});
//调用multer()返回的是一个multer的Multer对象
const upload = multer({
storage
});
app.post('/upload', upload.single("uploadFile"), (req, res, next) => {
console.log(req.body);
console.log(req.file);
res.write("success\r\n");
res.end("文件上传成功");
})此时在对应的中间件中无法通过
req.body获取到请求体中上传的文件数据,而是通过req.file或req.files。- 通过创建
storage传入指定destination需要自己先创建这个目录,而如果在声明upload的时候直接传入destination,而不使用storage,那么当这个目录本不存在时,会自动创建这个目录
- 通过创建
第三方中间件
如果希望记录请求日志,需要使用express开发的第三方库morgan
1 | const writeStream = fs.createWriteStream('./logs/access.log', { |
request参数解析
1 | // 获取params |
response响应数据
设置内容
调用res.end(chunk)要求chunk的类型必须为string或Buffer或Uint8Array
假使要传入一个对象,需要把它当成JSON进行解析
1 | // 比较麻烦的方法 |
res.json()可以发送一个json响应,当传递参数是一个数组或者对象等的时候,会被转换成json格式返回,它的作用和res.send()是一样的(最终调用的是res.send())。res.json()可以用于非对象(null、未定义等)的显式 JSON 转换。
res.end()和res.send()同:都可以用来结束响应
res.end([data[, encoding]][, callback]):这个方法实际上来自Node中http.ServerResponse的response.end()方法,传入data为对象的时候会报错,只能发送string或者Buffer类型的数据
res.send([body[,statusCode]]):body参数可以是Buffer、Object、String、Boolean 或 Array。该方法最终调用的也是http.ServerResponse的response.end()方法。在使用上来说,不需要关心响应数据的格式,因为Express内部对数据进行了处理
其他
- 设置状态码:
res.status(code)
Express的路由
使用express.Router来创建一个路由处理程序,一个Router实例拥有完整的中间件和路由系统(相当于mini-app),可以避免将所有代码逻辑写在app里
1 | // routers/users.js |
1 | // index.js |
静态资源服务器
Express可以作为静态资源服务器来进行部署
- 拷贝打包资源文件到Express项目根目录下
- 找到打包的文件夹,将其当作静态资源对应的文件夹:
app.use(express.static('./dist'));
Express的错误处理
将错误处理集中一起
调用next()时,如果传参,那么参数代表执行错误的中间件。如果不传参,作用就是执行下一个中间件。
当注册的是处理错误的中间件,回调函数有四个参数(err,req,res,next)。
1 | // 普通中间件 |
向next(new Error(msg))中传递的msg在错误的中间件中可以由err.message获取
部分源码解读
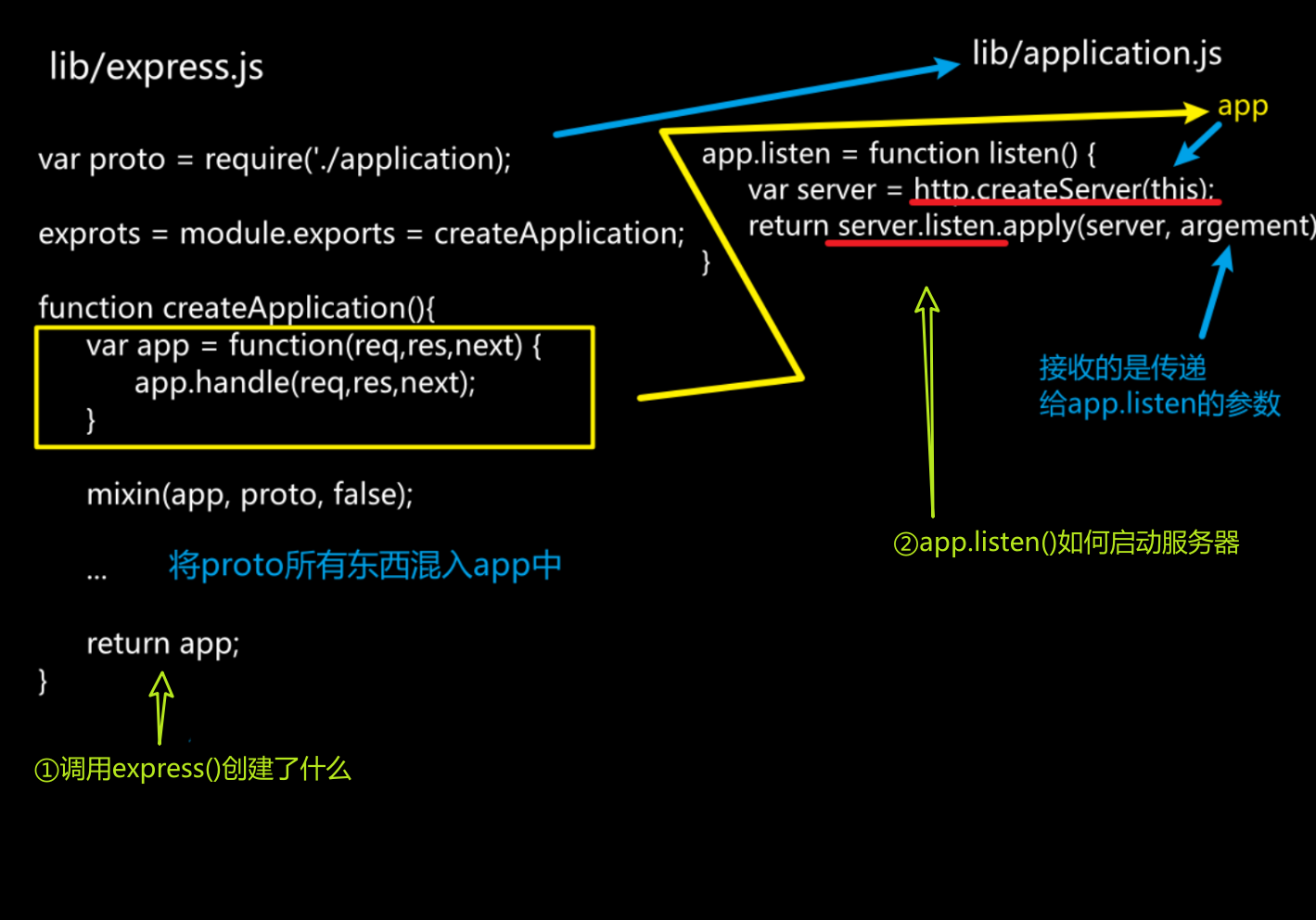
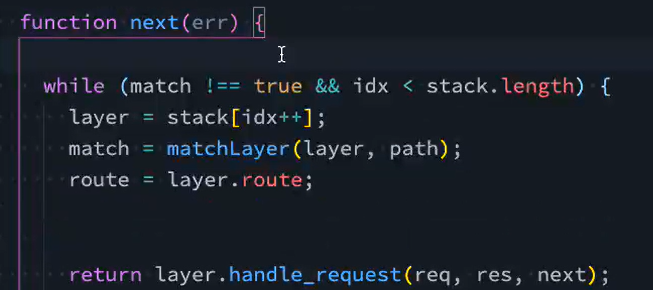
③app.use(中间件)内部发生了什么?
在lib/application.js文件中,app.use()通过调用this.lazyrouter()创建主路由router,在此之前完成对传入的多个函数作扁平化处理,然后遍历每个函数,调用router.use
lib/router.use执行的是router/index.js中的proto.use
在proto.use()中通过传入的fn,拿到所有回调callbacks,遍历其中每个fn,通过fn创建图层layer,将layer存入数组statck。
④用户发送了请求,中间件如何被回调?以及next为什么会执行下一个中间件?
用户发送请求后,执行app.listen函数中的app.handle
app.handle本质执行的是router.handle,对应lib/router/index.js中的proto.handle
proto.handle函数会初始化变量idx为0,取到前面提到的stack,(主动)调用函数体内声明的next函数。
next函数从stack中取出layer,查找匹配的中间件,找到匹配的中间件后调用layer.handle_request(req,res,next),对应的是lib/router/layer.js中的Layer.prototype.handle_request,在其中调用从layer中取出的fn,即我们注册的中间件
如果在注册中间件时调用next()就会进行idx++,继续寻找匹配的中间件,重复上述逻辑
Koa框架
Koa相对于express具有更强的异步处理能力;核心代码只有1600+行,是一个更加轻量级的框架,可以根据需要安装和使用中间件
安装:npm init -y -> npm install koa
简单使用:
1 | const Koa = require('koa'); //导出的是一个类(express导出的是一个函数) |
中间件
注册中间件
普通方式
Koa注册的中间件提供了两个参数
- cts:上下文,其中通过
ctx.request和ctx.response获取请求对象和响应对象 - next:本质上是一个
dspatch,类似于之前的next
在Koa中注册中间件,与Express不同,没有提供methods方式(app.get()、app.post()),也没有提供path方式(app.use('/home',(ctx,next)=>{})),也不能进行连续注册
分离路径和method
手动判断
对于请求方式和请求路径需要手动判断,通过ctx.request.url和ctx.response.method
通过ctx.response.body = ...来返回数据,如果没有这条命令将会返回NOT FOUND
ctx.body和ctx.response.body的区别?
ctx.body本质上执行ctx.response.body,这之间做了一个代理。还有很多属性都做了代理,但不是全部。
通过next(),注册下一个匹配的中间件
路由的使用
依赖第三方库,使用最多——koa-router,
可以使用methods方式、path方式,也可以连续注册
1 | // router/user.js |
1 | // index.js |
关于allowedMethods():
- 如果请求的是已经实现的method:会正常请求
- 如果请求的是put、delete、patch:会自动报错
Method Not Allowed,状态码405 - 如果请求的是link、copy、lock:会自动报错
Not Implemented,状态码501
参数解析:params和query
通过app.use注册中间件时,无法通过ctx.request.params获取params,可以通过ctx.request.query获取query。params需要自行解析,一般情况下结合路由使用
通过路由注册中间件时,ctx.request.params和ctx.request.query均可正常解析
参数解析:请求体数据
json和urlencoded
对于json和urlencoded类型的解析,需要依赖第三方库,常用koa-bodyparser
1 | const bodyParser = require('koa-bodyparser'); |
之后注册中间件时,直接通过ctx.request.body获取请求体数据即可
form-data
对于form-data类型的解析,需要依赖第三方库,常用koa-multer,用法可参照Express中的用法
1 | const multer = require('koa-multer'); |
同样不建议
upload.any()在全局注册通过
ctx.req.body获取而非ctx.request.body的原因:后者是Koa中自定义的request对象,而前者等同于Node原生中Http模块的request对象。multer解析body中把数据放在了
ctx.req.body中==koa-body==,但不能与koa-bodyparser同用
文件上传
类似于Express中的用法,同样借助第三方的koa-multer
1 | const Koa = require('koa'); //导出的是一个类(express导出的是一个函数) |
数据响应
响应结果
可通过ctx.response.body或ctx.body将相应主体设置为:string、Buffer、Stream(流数据)、Object||Array、null(不输出任何内容)之一
其他
- 状态码:设置
ctx.status或ctx.response.status,如果不设置,Koa自动将状态设置为200或204
静态服务器
在Koa中部署静态资源需要用到第三方库,koa-static,部署过程类似于express
1 | npm install koa-static --save |
在后面的开发过程中app.use(server('./dist'))有可能在访问localhost:8080(8080是打包的项目和服务器统一了的端口号,以vue项目为例见vue项目中vue.config.js中的devServer.port)时报错404。根据下图所示目录结构所作代码修改见下。
错误处理
Koa提供了多种错误处理方式,下面一种是关于监听错误的
1 | app.use((ctx,next) => { |
在真实开发中一般通过
ctx.app获取app而不是直接用,比如在路由里
部分源码解读
const Koa = require('koa');导出的是一个Application类,然后通过new Koa()创建app实例启动服务
app.listen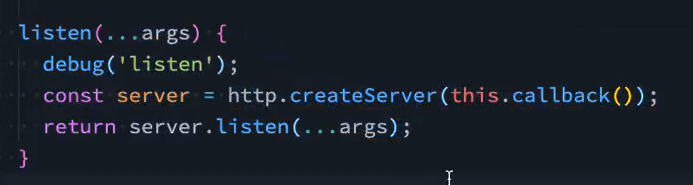
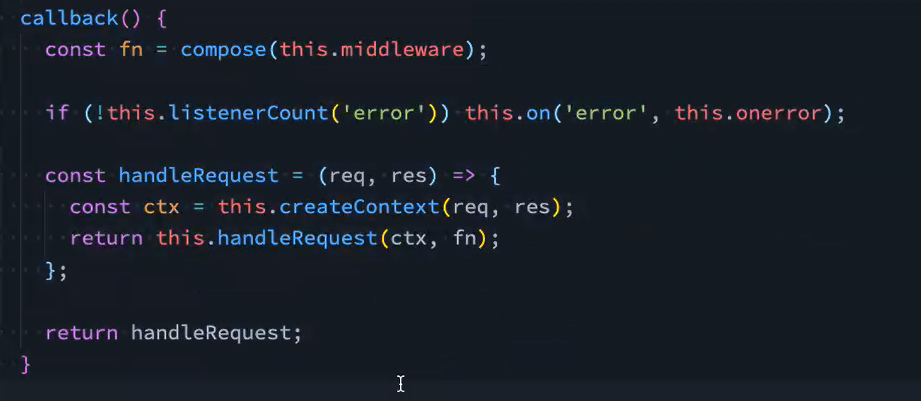
注册中间件
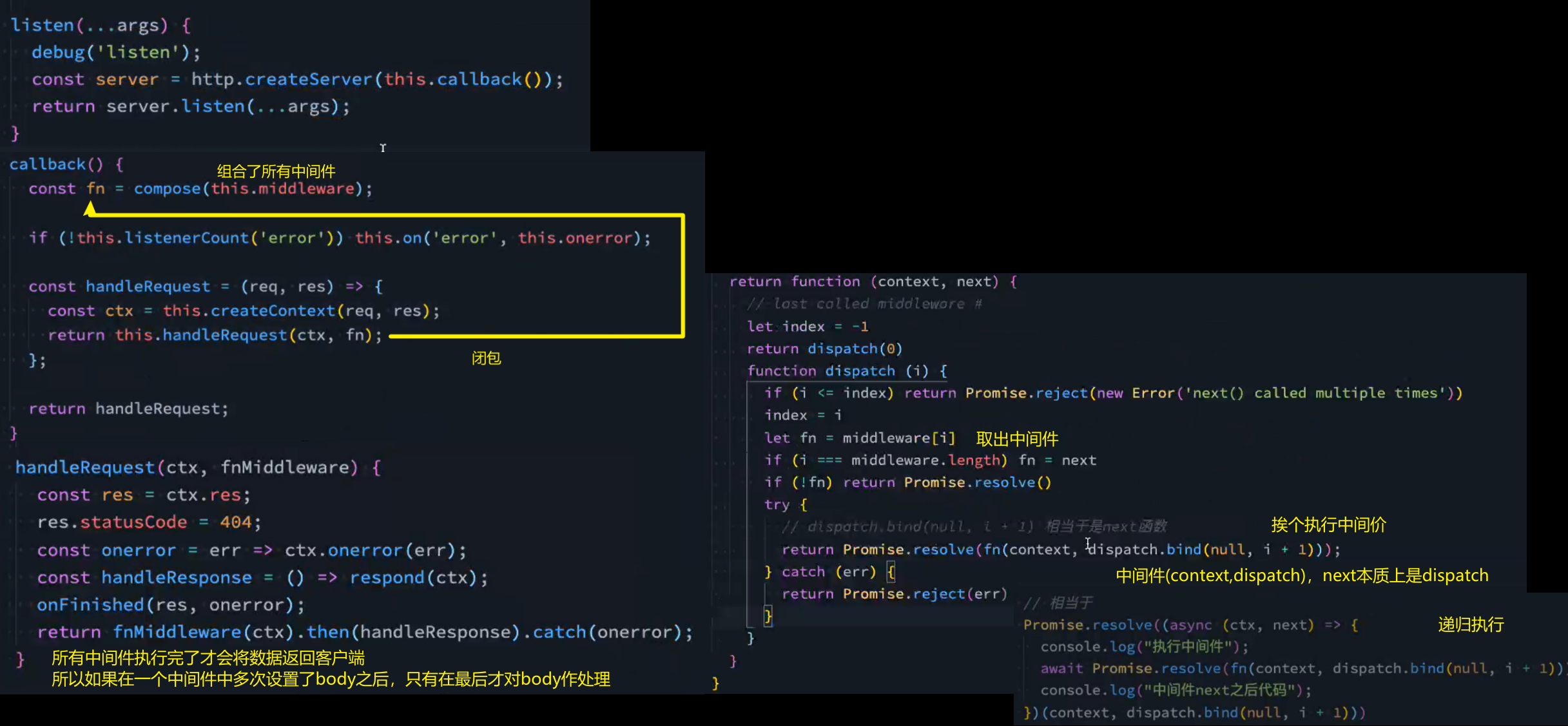
和Express对比

中间件的执行顺序
需求:注册三个中间件,修改响应数据,最后在第一个注册件中返回
(结合前面的源码理解)
Express
核心源码:
同步
1 | const express = require('express'); |
异步
当处理异步操作的时候,Express不好作处理
1 | const axios = require('axios'); |
在上述代码中,中间件middleware3的异步操作会被跳过然后直接回退到前面的中间件,即最终res.end(req.message);返回的结果只有aaabbb
在简单需求的时候将res.end(req.message);放在异步请求中(即then方法体内),还可以解决,但是遇到复杂需求则不适用,而且处理起来会比较麻烦。有一个解决方法是把middleware3当作一个函数在middleware1中调用
Koa
同步
1 | const Koa = require('koa'); |
异步
默认处理时(像express那样),一样会跳过异步代码
在前面解读代码的dispatch函数中返回Promise,即调用next()会返回一个Promise,所以可以有一下方案:
1 | const Koa = require('koa'); |
express源码中next方法的设计是同步的,所以同样的方案在express中不起效
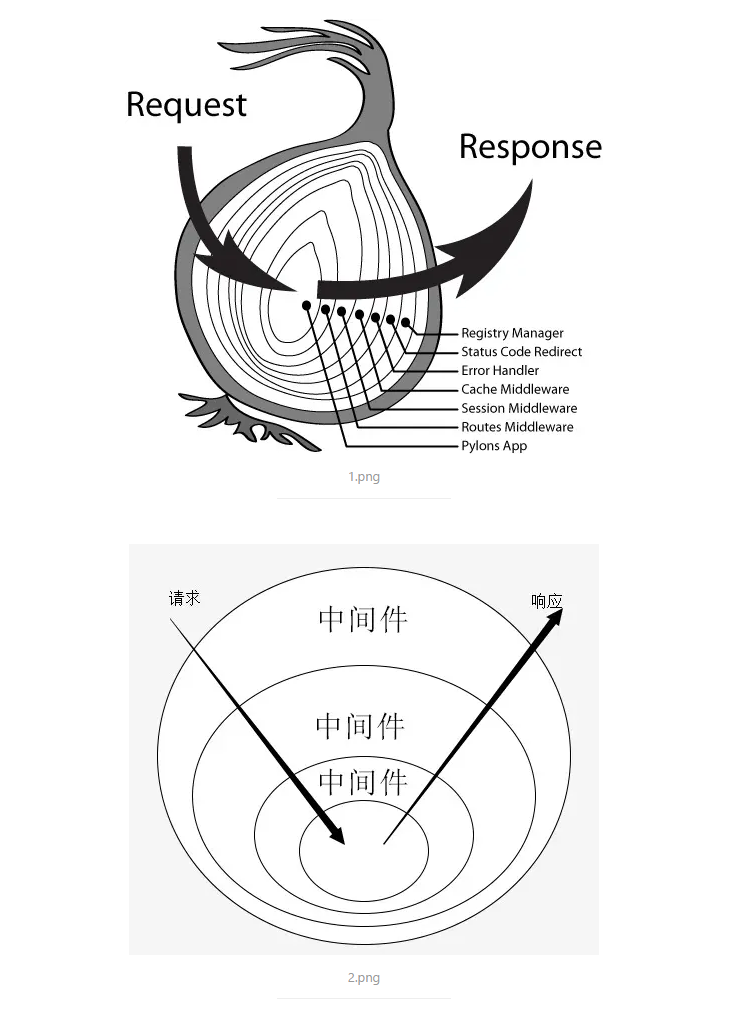
Koa洋葱模型
Node使用MySQL
MySQL中的对象和数组类型
一对多,场景:一个型号的手机对应其品牌的多条数据,将这些联合查询到的数据转化成一个对象
1
2
3
4
5SELECT
products.id id, products.title title, products.price price,
JSON_OBJECT('id', brand.id, 'name', brand.name, 'website', brand.website) brand
FROM products
LEFT JOIN brand ON products.brand_id = brand.id;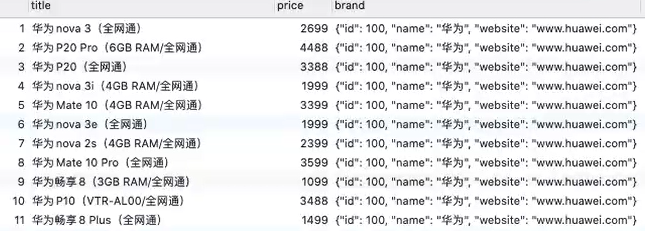
多对多,场景:一个学生可以选修多门课程,每门课程对应多条数据。将查询到的多条数据,组织成对象,放入到一个数组中
1
2
3
4
5
6
7SELECT
stu.id, stu.name, stu.age,
JSON_ARRAYAGG(JSON_OBJECT('id', cs.id, 'name', cs.name, 'price', cs.proce))
FROM students stu
JOIN students_select_courses ssc ON stu.id = ssc.student_id
JOIN courses cs ON scc.course_id = cs.id
GROUP BY stu.id;
注意:分组用的GROUP BY语句不能少
部分数据可能并不对应有数组或者对象数据,为了能够直接返回null,而非{id:null, name:null}的形式,可以使用IF语句
问题描述
有时候多张表连接,会出现数据重复的问题,比如:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
m.id id, m.content content, m.createAt createTime, m.updateAt updateTime,
JSON_OBJECT('id', u.id, 'name', u.name) author,
IF(COUNT(c.id),JSON_ARRAYAGG(
JSON_OBJECT(
'id', c.id, 'content', c.content, 'commentId', c.comment_id, 'createTime', c.createAt,
'user', JSON_OBJECT('id', cu.id, 'name', cu.`name`)
)
),NULL) comments,
IF(COUNT(l.id),JSON_ARRAYAGG(
JSON_OBJECT('id', l.id, 'name', l.name)
),NULL) labels
FROM moments m
LEFT JOIN users u ON m.user_id = u.id
LEFT JOIN comments c ON c.moment_id = m.id
LEFT JOIN users cu ON c.user_id = cu.id
LEFT JOIN moment_label ml ON ml.moment_id = m.id
LEFT JOIN labels l ON ml.label_id = l.id
WHERE m.id = 10
GROUP BY m.id;其中相关表的数据:
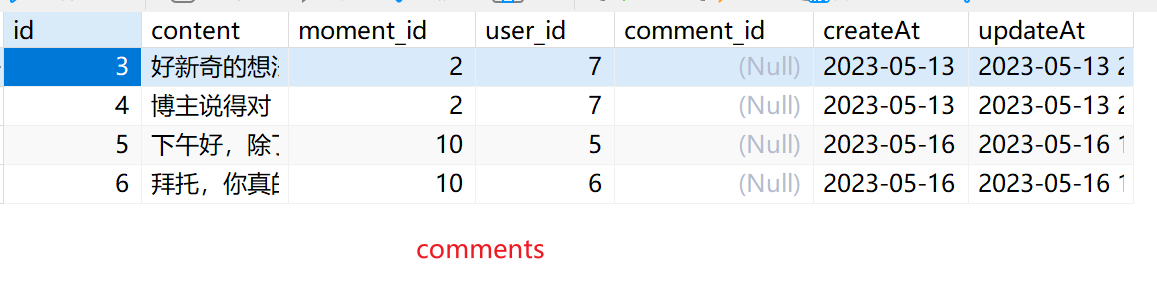

查询结果:

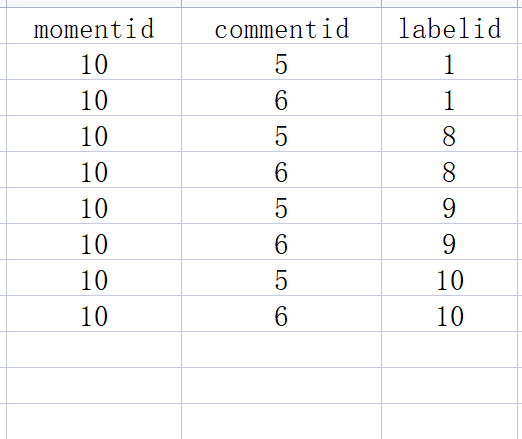
理解:本质上多张表之间的连接还是一条一条数据连着的,JSON_ARRAYAGE和JSON_OBJECT只是定义了我要取到的数据形式应该是怎么样子的。当查询条件为moment_id为10时,在左连接comments表的时候,会有两条数据,后来左连接moment_label时会有四条数据,所以会出现上述数据重复的情况,因为是先连接的comments后形成的新表去连接的moment_label表,前头两条数据分别去找后面的四条数据连接。(被干扰了)
把上述连接的最后结果理解成下面这样的:
解决方案:
对于comments和labels的查询和展示分开两个接口
使用子查询
(1)子查询comments,放在labels前后都没有关系,下面的示例是放在了labels的后面
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
m.id id, m.content content, m.createAt createTime, m.updateAt updateTime,
JSON_OBJECT('id', u.id, 'name', u.name) author,
IF(COUNT(l.id),JSON_ARRAYAGG(
JSON_OBJECT('id', l.id, 'name', l.name)
),NULL) labels,
(SELECT IF(COUNT(c.id),JSON_ARRAYAGG(
JSON_OBJECT(
'id', c.id, 'content', c.content, 'commentId', c.comment_id, 'createTime', c.createAt,
'user', JSON_OBJECT('id', cu.id, 'name', cu.`name`))
),NULL) FROM comments c LEFT JOIN users cu ON c.user_id = cu.id WHERE c.moment_id = m.id) comments
FROM moments m
LEFT JOIN users u ON m.user_id = u.id
LEFT JOIN moment_label ml ON ml.moment_id = m.id
LEFT JOIN labels l ON ml.label_id = l.id
WHERE m.id = 10
GROUP BY m.id;(2)子查询labels,有一点要注意的是,由于对象中的数据是从labels表取的,所以要跟moment_label右连接,因为跟moments表有关系的是moment_label表。
这个写法是根据上面第一种然后自己推导到labels上的,查询结果是一样的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
m.id id, m.content content, m.createAt createTime, m.updateAt updateTime,
JSON_OBJECT('id', u.id, 'name', u.name) author,
IF(COUNT(c.id),JSON_ARRAYAGG(
JSON_OBJECT(
'id', c.id, 'content', c.content, 'commentId', c.comment_id, 'createTime', c.createAt,
'user', JSON_OBJECT('id', cu.id, 'name', cu.`name`)
)
),NULL) comments,
(SELECT IF(COUNT(l.id),JSON_ARRAYAGG(
JSON_OBJECT('id', l.id, 'name', l.name)
),NULL) FROM labels l RIGHT JOIN moment_label ml ON ml.label_id = l.id WHERE ml.moment_id = m.id) labels
FROM moments m
LEFT JOIN users u ON m.user_id = u.id
LEFT JOIN comments c ON c.moment_id = m.id
LEFT JOIN users cu ON c.user_id = cu.id
WHERE m.id = 10
GROUP BY m.id;
IF语句
用法一:IF表达式
IF(expr1, expr2, expr3)。如果expr1为TRUE,则返回值为expr2,否则返回expr3用法二:IFNULL语句
IFNULL(expr1, expr2)。如果expr1不为null,则返回expr1,否则返回expr2用法三:IF…ELSE…语句
1
2
3
4
5IF search_condition THEN
statement_list
ELSE
statement_list
END IF;search_condition表示条件,如果成立时执行THEN后面的statement_list语句,否则执行ELSE后面的statement_list语句。
search_condition是一个条件表达式,可以由条件运算符组成,也可以使用AND、OR、NOT对多个表达式进行组合
mysql2
在Node中执行SQL语句可以借助两个库:mysql、mysql2。mysql是最早的Node连接MySQL的数据库驱动,mysql2是在mysql的基础之上,进行了很多的优化、改进。mysql2兼容了mysql的API,并且提供了一些附加功能。

基本用法
1 | const mysql = require('mysql2'); |
默认情况下,建立连接之后会一直等待结果,不会停止。如果需要终止连接,有两种方式。
1 | // 方法一 |
预处理语句(Prepared Statement)
1 | const mysql = require('mysql2'); |
conn.execute内部执行的是prepare和query方法,如果再次执行conn.execute语句,它将会从LRU(Least Recently Used) Cache中获取,省略了编译Statement的时间来提高性能
连接池(Connection Pools)
当我们有多个请求的时候,连接可能正在被占用。
mysql2为我们提供了连接池,可以在需要的时候自动创建链接,并且创建的连接不会被销毁,会回收到连接池中,后续可以继续使用。所以我们不需要每次一个请求都去创建一个新的连接然后又自己销毁。
1 | const mysql = require('mysql2'); |
connectionLimit参数代表的是连接的最大创建个数。连接池并不是一开始就创建该数目的连接,而是当连接不够用的时候才会自动帮我们创建,直到达到limit上限
在上述的代码中,是通过回调函数的方式获取结果的。在实际开发中为了避免回调地狱的问题,使用Promise用法。用法之一如下:
1 | conn.promise().execute(statement, [22, 'D']).then(([results]) => { |
其中,[results]用了解构,因为promise成功结果还包括了其他一些数据
其他方法:[github node-mysql2文档](sidorares/node-mysql2: fast mysqljs/mysql compatible mysql driver for node.js (github.com))
认识ORM

当使用ORM时,不需要编写SQL语句。而是通过操作我们自己定义的类(与表之间存在映射关系)的方法,可以借助ORM库自动生成SQL语句,然后传给mysql2驱动,再传给数据库
每条数据都是一个实例
基本使用
1 | const { Sequelize } = require('sequelize'); |
单表操作
早期版本常用sequelize.define获取一个类,但是ES6中提供了class关键字定义类,故可以使用Extending Model的方法。
1 | const { Sequelize, DataTypes, Model} = require('sequelize'); |
- {2}、{3}在自动生成的sql语句中会自动添加
createdAt和updatedAt两个字段,如果在设计表的过程中没有这两个,那么就如{2}、{3}所示即可忽略
查询数据
1 | const {Op} = require('sequelize'); |
插入数据
1 | async function queryProducts() { |
更新数据
1 | async function queryProducts() { |
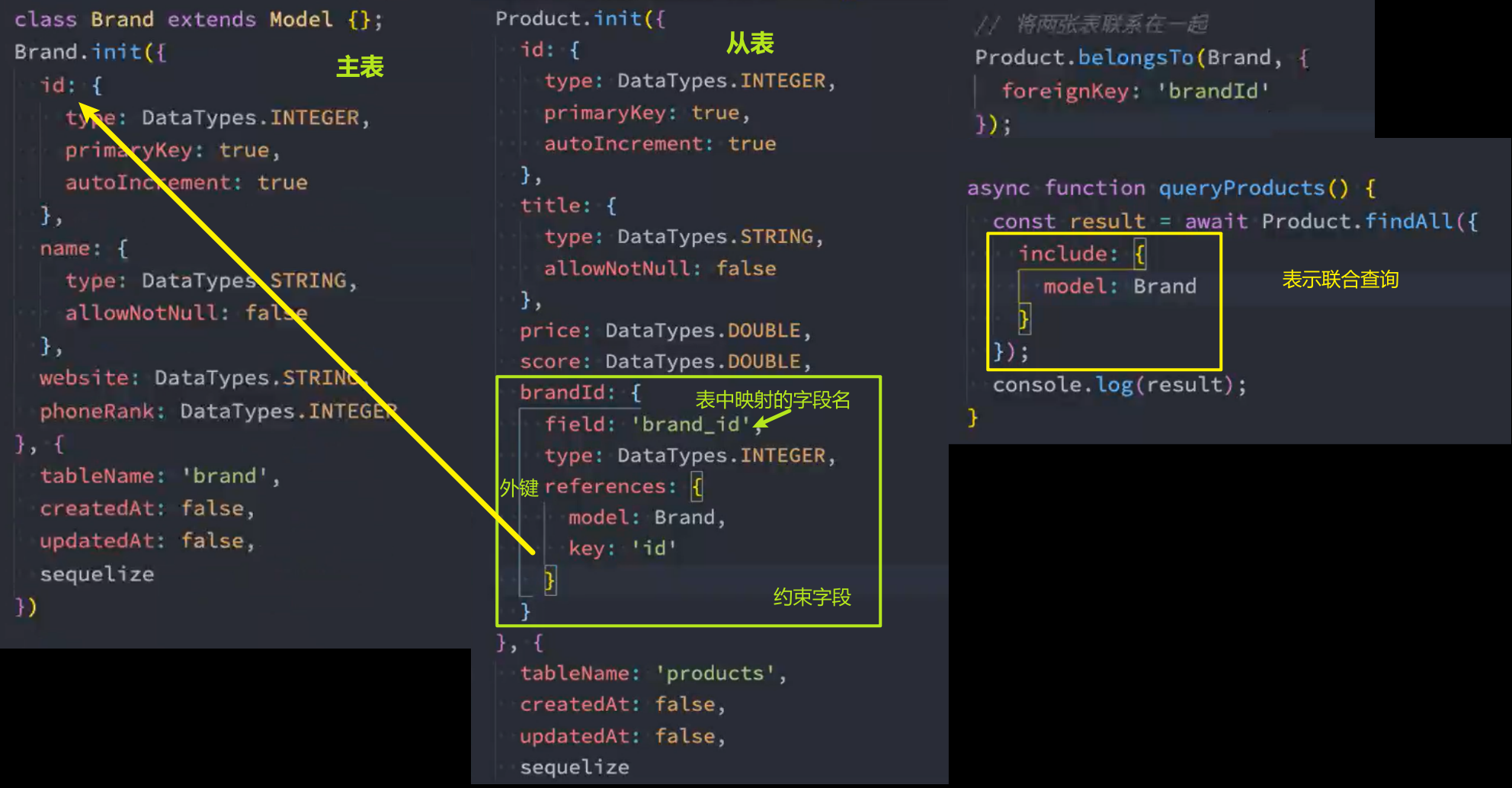
一对多操作
参照前面MySQL中的对象和数组类型一节的示例场景
多对多操作
建立映射关系
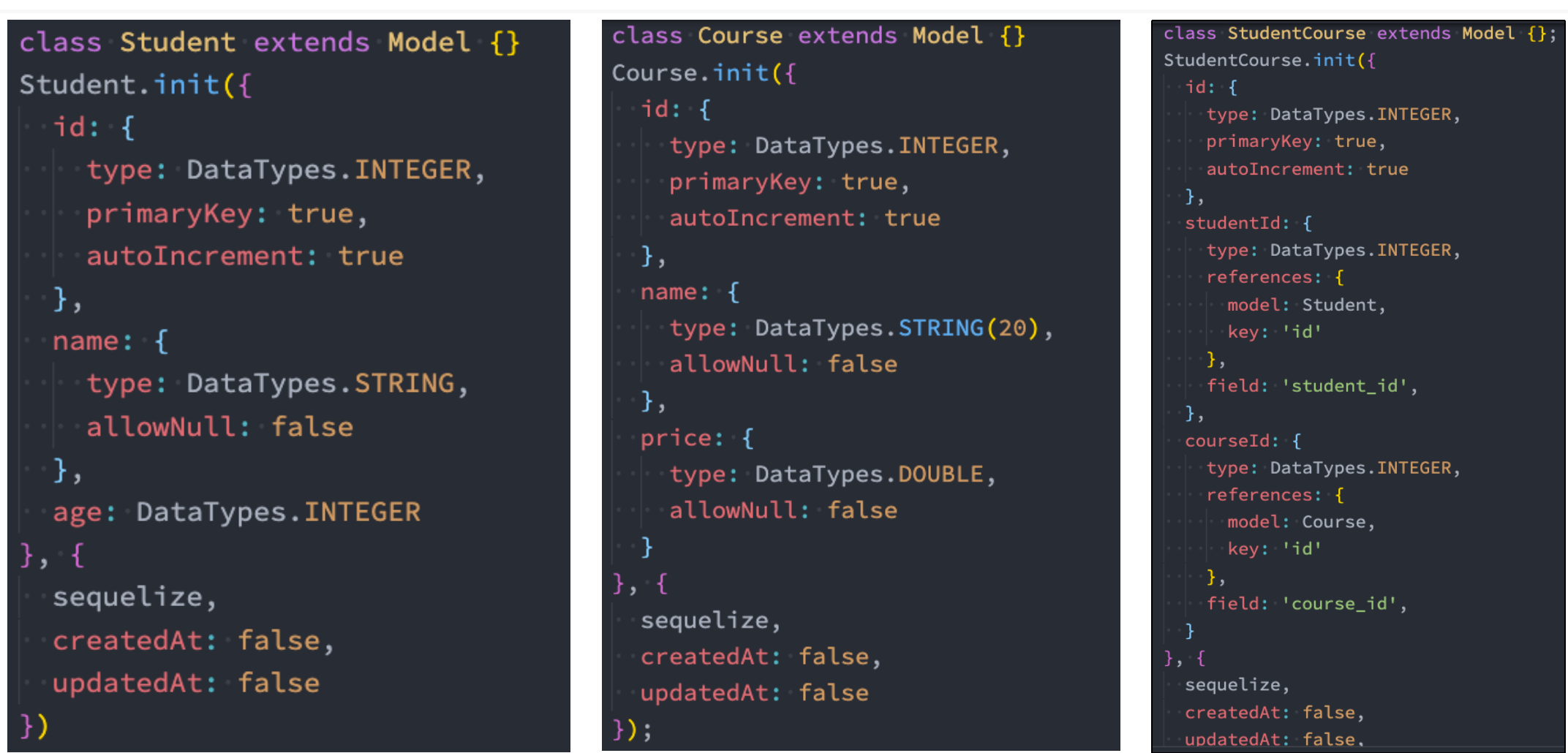
建立表关系

codehub项目实战
云服务器自动化部署
踩过的坑及解决方案
https://zhuanlan.zhihu.com/p/609882788(特别是第四点!!改了用户是root之后systemctl start jenkins报错)
https://blog.csdn.net/weixin_44519874/article/details/118380515评论区
pm2配置文件 ecosystem.config.js
【未解决】
测试coderhub项目的过程中,涉及上传文件的两个接口无法正常使用
具体说明:apipost会报错
err: socket hang up,无法修改数据库coderhub中的avatars和files两个表,但是项目文件中对应的uploads下的两个文件夹images和avatars都会添加新的文件。(一开始的时候成功过一次就是给id为8的用户传过一次头像,那个时候avatars和users两个表都改了,还有sql语句中对于涉及文件路径的应该要将原本的
localhost:8000修改成服务器的ip地址和端口号吧).env的配置中,APP_PORT和APP_HOST要修改
gitbash连接服务器和mysql一会不用总是断开。。。
一些个学习过程中的坑
download模板之后手动
npm run serve报错
解决方案:降低Node版本,可使用nvm工具管理多版本
学习Writable的过程中,遇到以下问题
学习代码用的是16.14.1版本,
createWriteStream方法中options参数的flags为a时,所有write操作都是把传入的内容添加文件末尾(所以start也无效了)。如果flags的值为r+,实现效果是可以在start指定为位置插入,但是新插入的内容会替换文件中原本位置上的内容。而且在某些时候会把文件搞乱码api文档指路:File system | Node.js v16.14.1 Documentation (nodejs.org)
PS:两个版本下,VScode都没有提示
createWriteStream方法中的options参数有flags暂未解决
学习Express中使用Multer进行文件上传时,根据课程中的学习代码
app.post('/upload',upload.sigle('file'),(req,res,next)=>{})会报错Error: Unexpected end of form解决方案:将
upload.sigle('file')移至回调函数后面,作为第三个参数出错原因:之前把
upload.any()作为全局中间件使用,即app.use(upload.any()),虽然上面的方法也行得通,但是文档里面已经说明了不要把multer当成全局中间件使用。所以为了规范,正常把uploaad.single()和upload.array()当作第二个中间件就好,不用特意放到末尾。关于
upload.any()和upload.none()的一些使用场景分析:当需要上传文件的时候,结合上面说的内容,只有把这两个中间件放在
app.post()的最后才能正常获取req.body和req.any()当不需要上传文件的时候,放在哪里不影响
req.body和req.any()的获取顺序的区别?原因?