前端 Vue3 + ElementPlus, 服务端 Nodejs20 ,实现大文件上传、秒传、断点续传等
前言
上传文件体积越大,耗时越长,可能会存在各种各样的风险,例如因为网络波动,如果上传中途掉包,可能会导致文件上传失败,前面上传的也前功尽弃。或者可能,上传过程中,服务器容易出现内存溢出。某些服务器处理文件上传是在接收到后直接写到内存里的,并没有先写进文件系统,这会导致在文件很大的时候占用过多内存,给服务端造成很大的压力,甚至可能导致内存崩溃。大文件上传处理不好不仅带来性能问题,同时也严重影响用户体验。
大文件上传
整体思路
前端
利用Blob.prototype.slice 方法,将大文件分成一个个切片,然后借助 http 的可并发性,同时上传多个切片。这样从原本传一个大文件,变成了并发传多个小的文件切片,可以大大减少上传时间,同时如果单个切片上传失败也不会影响到其它的内容。
由于是并发,传输到服务端的顺序可能会发生变化,因此我们还需要给每个切片记录顺序,同时也便于服务端的切片合并工作。
显然,为了提高效率和保证文件上传的安全性,我们需要给文件唯一的标识符,像是单纯结合文件名、上传时间等信息是不靠谱的。这里采用计算文件md5值得方案,根据文件内容,生成唯一标识符。
服务端
负责接受前端传输的切片,并在接收到所有切片后,合并所有切片
这里引伸出两个问题
- 如何判断合并切片的时机
- 如何合并切片
第一个问题有两种思路。
- 当服务端根据前端传过来的信息,在接受切片到最大数量时自动合并。
- 前端额外发一个请求,主动通知服务端进行切片的合并
第二个问题,需要考虑将各切片的内容放在它该出现的位置。这里可以使用 Nodejs 的读写流( readStream 和 writeStream),对应切片的顺序,将所有切片的流传输到最终文件的流里
文件切片分包,再组合,其实也就是TCP的底层逻辑
前期工作
前端
上传控件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <template>
<div>
<input type="file" @change="handleFileChange" />
<el-button @click="handleUpload">upload</el-button>
</div>
</template>
<script setup>
const container = reactive({
file: null
});
const handleFileChange = (e) => {
const [file] = e.target.files;
if (!file) return;
container.file = file;
};
const handleUpload = async () => {};
</script>
|
请求逻辑封装
考虑到通用性,前端不使用第三方请求库,而是用原生XMLHttpRequest做一层简单的封装来向服务端发送请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
const baseUrl = "http://localhost:8080/upload";
const request = ({
url,
method = 'POST',
data,
headers = {}
}) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
url = baseUrl + url;
xhr.open(method, url);
Object.keys(headers).forEach(key => xhr.setRequestHeader(key, headers[key]));
xhr.send(data);
xhr.onload = e => {
if (xhr.status >= 200 && xhr.status < 300) {
resolve({
data: e.target.response
});
} else {
reject(new Error(`Request failed with status ${xhr.status}`));
}
};
xhr.onerror = () => {
reject(new Error('Network error'));
};
})
}
export default request;
|
服务端
服务端开发选择Koa2框架,其他基础配置见 Koa2服务端基本配置(持更)
路由配置
1
2
3
| const Router = require('koa-router');
const uploadRouter = new Router({ prefix: '/upload'})
module.exports = uploadRouter;
|
跨域配置
上传切片
前端
思路:将大文件切片,并为每个切片添加标识符hash,格式是文件hash-切片索引,挨个发送到服务端。
切割文件
抽离方法
1
2
3
4
5
6
7
8
9
10
11
|
export function createFileChunk(file, size = 10 * 1024 * 1024) {
const fileChunkList = [];
let cur = 0;
while (cur < file.size) {
fileChunkList.push({ file: file.slice(cur, cur + size) });
cur += size
}
return fileChunkList
}
|
切割文件是点击上传按钮的要做的第一件事:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <!-- UploadFile.vue-->
<template>
<el-button @click="handleUpload">upload</el-button>
</template>
<script setup>
// 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
} catch (error) {
console.log(console.error());
}
};
</script>
|
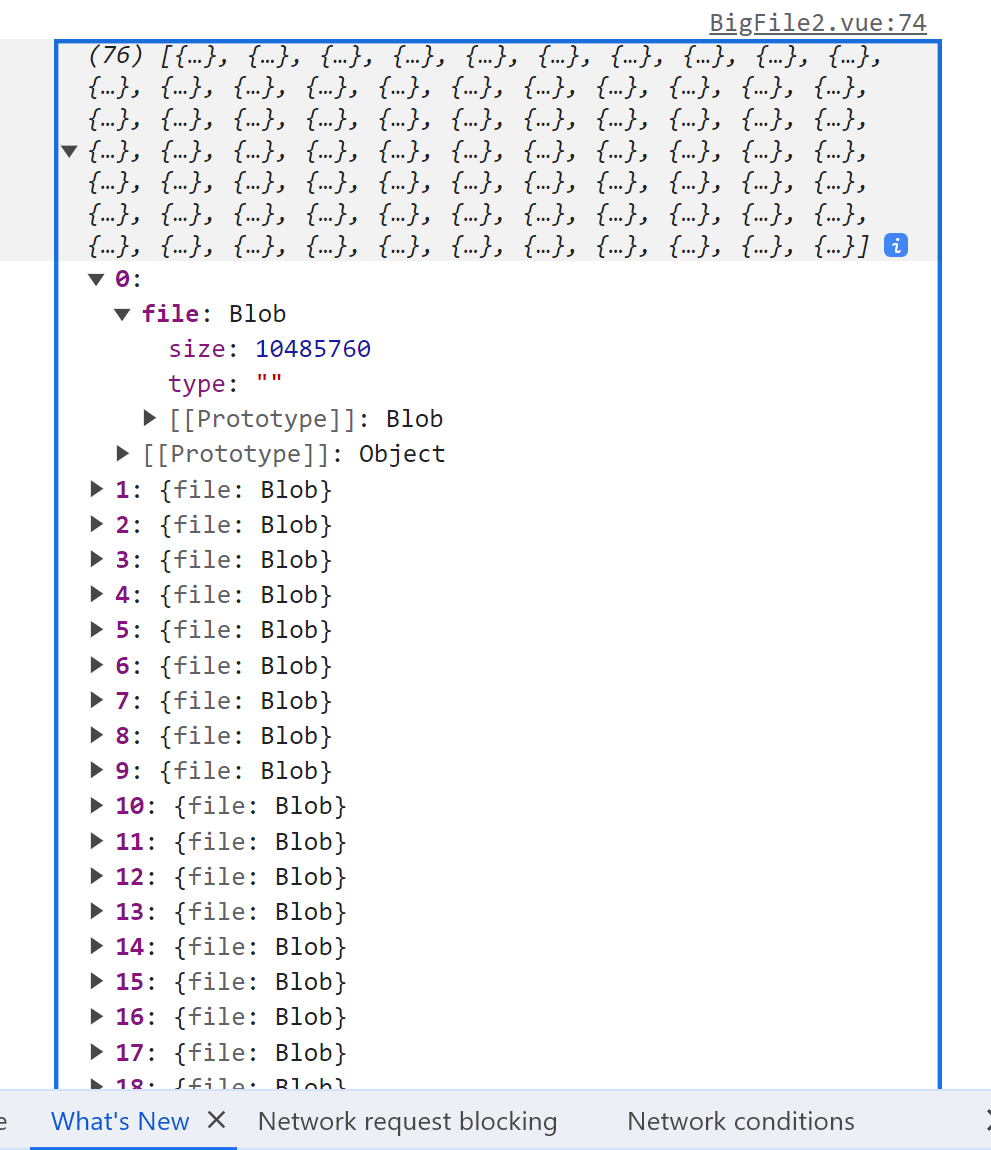
调用 createFileChunk 方法,生成文件切片数组 fileChunkList ,该数组打印如下图所示:
计算md5值
无论是上传过程中涉及到文件路径的操作还是后续的秒传处理等操作,如果使用文件名作为上传文件的标识符,那么显然文件内容不变文件名改变,或者文件内容改变了但文件名没有变,都会对我们的工作造成影响。所以我们需要一个与文件内容相关的唯一标识符来表示该文件,这里用到第三方库 spark-MD5,在前端根据文件内容生成的 MD5 值作为文件的 hash 值。
考虑到如果上传的是一个超大文件,读取文件内容计算hash是非常耗时的,并且会引起UI的阻塞,所以我们使用 web-worker 另外开辟一个 worker 线程完成这个计算任务。
主线程和 Worker 之间的通信是通过消息传递机制进行的。主线程通过postMessage方法发送消息给 Worker,Worker 使用 onmessage 事件监听并处理这些消息。同样,Worker 也可以使用 postMessage 方法向主线程发送消息,主线程使用 onmessage 事件监听并处理这些消息。
具体来说,主线程使用 postMessage 给 worker 线程传入所有切片 fileChunkList,并使用 onmessage 事件拿到计算进度 percentage 和文件 md5 值 hash,这里只有当percentage达到了100%,Worker 才把 hash 计算完毕并返回,其他时候都只传 percentage。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <script setup>
+ let hashPercentage = ref(0); // 计算 md5 值的进度
+ // 生成文件hash(web-worker)
+ const calculateHash = fileChunkList => {
+ return new Promise(resolve => {
+ // 添加worker属性
+ container.worker = new Worker("/hash.js");
+ container.worker.postMessage({ fileChunkList });
+ container.worker.onmessage = e => {
+ const { percentage, hash } = e.data;
+ hashPercentage = percentage;
+ if (hash) {
+ resolve(hash);
+ }
+ };
+ });
+ }
// 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
+ container.hash = await calculateHash(fileChunkList);
} catch (error) {
console.log(console.error());
}
};
</script>
|
实例化 web-worker 时,Worker 文件应该是一个单独的 js 文件,并且不能跨域,即 Worker 脚本必须与主页面位于一个域下,在这里单独创建一个hash.js 文件在 pulic 目录下。另外由于 Web Worker 不具有 DOM 访问权限,某些第三方库可能无法在 Web Worker 中正常工作,所以我们使用 importScripts 函数导入外部脚本,这里是导入 public 目录下存放的 spark-md5的脚本 spark-md5.min.js。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
self.importScripts("/spark-md5.min.js");
self.onmessage = e => {
const { fileChunkList } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
let percentage = 0;
let count = 0;
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(fileChunkList[index].file);
reader.onload = e => {
count++;
spark.append(e.target.result);
if (count === fileChunkList.length) {
self.postMessage({
percentage: 100,
hash: spark.end()
});
self.close();
} else {
percentage += 100 / fileChunkList.length;
self.postMessage({
percentage
});
loadNext(count);
}
};
};
loadNext(0);
}
|
在 Worker 中,接收文件切片 fileChunkList,利用 fileReader 读取每个切片的 ArrayBuffer 并通过 append 方法不断传入 spark-md5 中。每读完并读取了一个切片,通过 postMessage 向主线程发送一个进度事件,count的值取到切片数组的长度时,表示所有切片内容都添加完成了,通过 spark.end() 计算文件 md5 值,将最终的 hash 发送给主线程。
网上很多相关博客都有写道:
- “spark-md5文档中要求传入所有切片并算出hash值,不能直接计算整个文件,否则即使不同文件也会有相同hash值”。
关于这个说法,在 NPM 上找到的(可能)相关原文是:

但这些博客基本都没有具体解释为什么,应该要研究原理,有一些长篇的原理解释看的头疼,问了gpt,姑且先这么理解吧
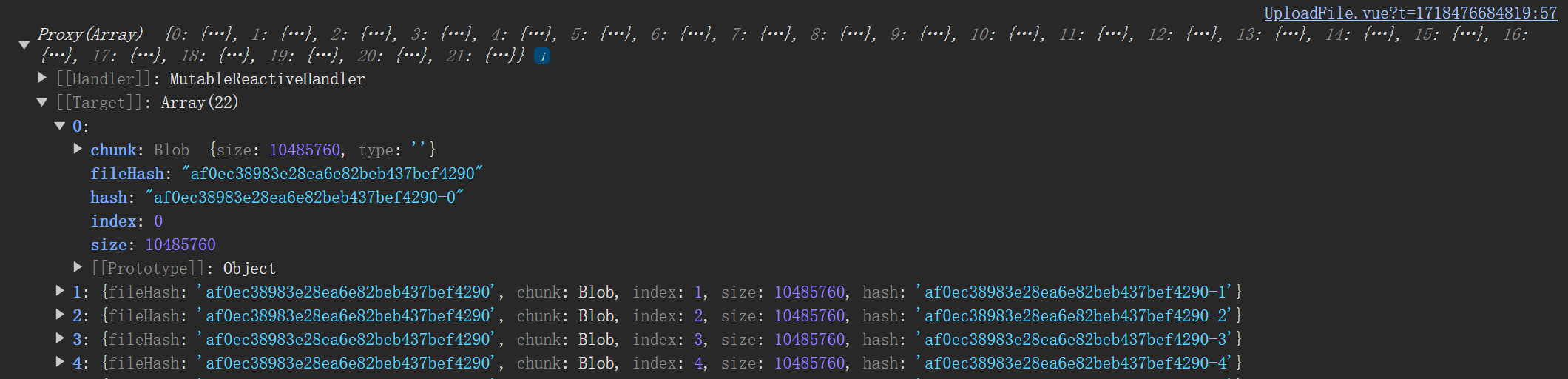
根据 fileChunkList 数组,生成对象数组 data ,存放文件切片的信息并添加标识hash。data 数组中每个元素对象包含两个属性,chunk(文件切片本身)和 hash(文件 md5 值 + 下标)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| <script setup>
+ const data = ref([]);
// 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
container.hash = await calculateHash(fileChunkList); // 计算文件md5
+ data.value = fileChunkList.map(({ file }, index) => ({
+ fileHash: container.hash,
+ chunk: file,
+ index,
+ size: file.size,
+ hash: container.hash + '-' + index,
+ }));
} catch (error) {
console.log(console.error());
}
};
</script>
|
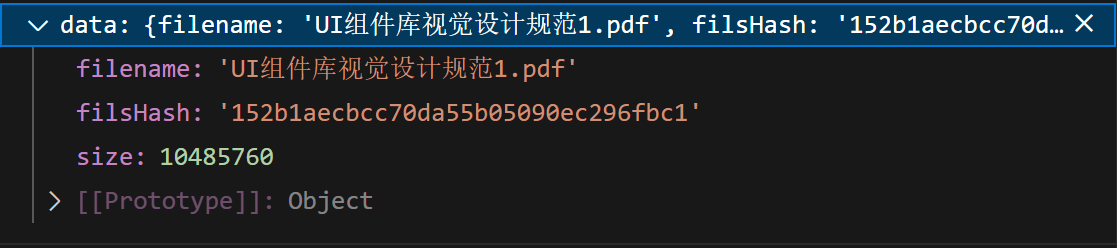
container.hash 是计算好的文件 md5 值。data 打印结果如下:
整理好切片信息 data 后,触发 uploadChunks方法,上传所有切片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| <script setup>
// 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
container.hash = await calculateHash(fileChunkList); // 计算文件md5
data.value = fileChunkList.map(({ file }, index) => ({
fileHash: container.hash,
chunk: file,
index,
size: file.size,
hash: container.hash + '-' + index,
}));
+ await uploadChunks();
} catch (error) {
console.log(console.error());
}
};
</script>
|
并发上传切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| <script setup>
// 上传切片
const uploadChunks = async () => {
const requestList = data.value
.map(({ chunk, hash, index }) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("hash", hash);
formData.append("fileHash", container.hash);
formData.append("filename", container.file.name);
return { formData, index }
})
.map(({ formData }) =>
request({
url: "/file",
data: formData
})
);
// 并发请求
await Promise.all(requestList);
}
</script>
|
- 创建一个数组
requestList,存放调用 request 方法上传每一个切片的所返回的 promise 对象。通过遍历 data 数组,第一次 map 生成的数组包含上传每一个切片对应的请求数据 formData(包含文件切片内容、切片hash、文件hash、文件名),第二次 map 调用 request 方法一一上传formData,每次上传都会得到一个 request 方法返回的 promise 对象。因此 requestList 数组最终存储的是处理每个切片上传的 promise 对象。
- 并发请求:
Promise.all(requestList),只有当所有切片都上传成功了才会成功
服务端
接收切片
思路:multiparty库,用来解析 content-type 为 multipart/form-data,的 http 请求,即文件上传。因此我们用来处理前端传来的 formData ,接收文件切片。
这里想先记录一下一开始实现的做法(注意是有报错的哈)——直接在中间件里面写解析参数接收文件的逻辑:
1
2
3
4
5
6
7
8
9
10
| uploadRouter.post('/', async (ctx, next) => {
const multipart = new multiparty.Form();
multipart.parse(ctx.req, async (err, fields, files) => {
if (err) {
return;
}
console.log(fields);
console.log(files);
});
});
|
关于 multiparty 库的使用,这里不过多赘述,只解释一下涉及到的参数:
fields:保存了 formData 中非文件的字段files :保存了 formData 中的文件
上述代码接收某一个切片的打印结果如下:
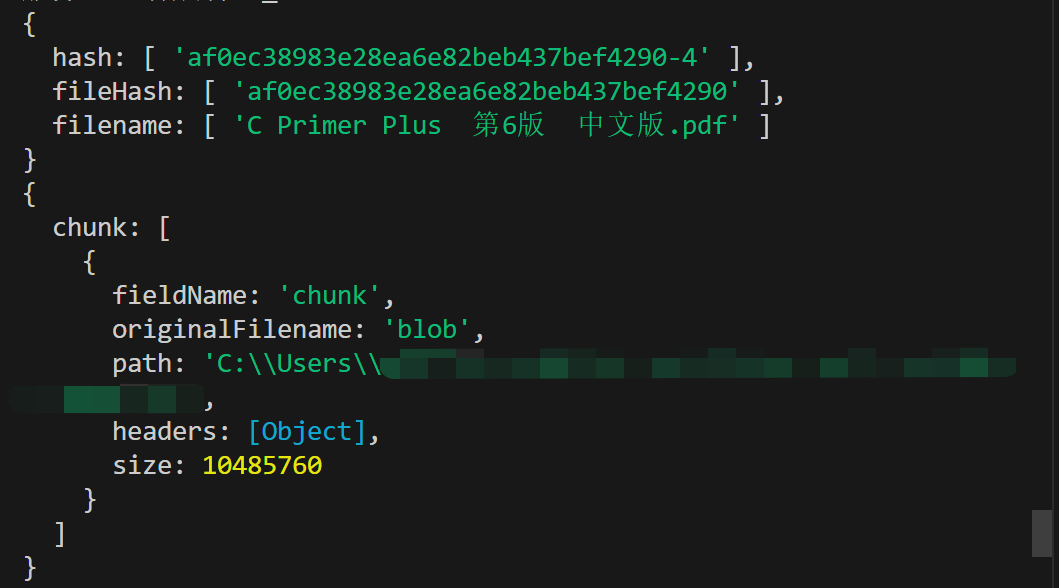
前端为 formData 添加了四个字段,分别是 chunk、hash、fileHash、filename,在这里一一对应上。在 chunk 中,path 表示存储临时文件的路径。
服务端接收并存储文件切片的具体流程是:
- 预先通过
fse.mkdirs 在服务端创建一个存储文件切片的文件夹,以chunkDir_ 为前缀,文件hash为后缀,即文件夹的命名为chunkDir_ + fileHash。
- 通过
fse.move 将切片文件从存储临时文件的路径(path)移动到服务端新建的切片文件夹中。
- 处理操作成功或失败的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| const multiparty = require('multiparty');
const path = require('path');
const fse = require('fs-extra');
const UPLOAD_DIR = path.resolve(__dirname, "../../", "public/upload");
uploadRouter.post('/file', async (ctx, next) => {
const multipart = new multiparty.Form();
multipart.parse(ctx.req, async (err, fields, files) => {
if (err) {
console.error(err);
ctx.body = {
code: 500,
msg: "Failed to parse request"
}
return;
}
const [ chunk ] = files.chunk;
const [ hash ] = fields.hash;
const [ fileHash ] = fields.fileHash;
const chunkDir = path.resolve(UPLOAD_DIR, 'chunkDir_' + fileHash);
if (!fse.existsSync(chunkDir)) {
await fse.mkdir(chunkDir);
}
try {
await fse.move(chunk.path, `${chunkDir}/${hash}`);
ctx.body = {
code: 200,
msg: "Successfully uploaded"
}
} catch (error) {
console.error(error);
ctx.body = {
code: 500,
msg: "Failed to receive file chunk"
}
}
});
});
|
这个时候接口的调用其实是成功的,可以看到文件切片确实上传成功了。但是有一个问题,控制台会报调用接口404。
在 Koa 中,接口调用成功了,但是报 404。经过检查,上述代码逻辑中,异步操作均使用了 async/await 处理,所以第一时间想到的是响应结果 ctx.body 的问题,ctx.body的处理是否有不妥当的。
在处理文件上传时,我们需要接收完所有文件数据后才响应结果给前端,而在multipart.parse 中进行接收文件是一项异步操作。查找资料的时候,看到这样的说法,“不要把 ctx.body 写在异步操作里”以及“koa的中间件对异步操作是返回一个Promise对象处理的”。我的理解是,在中间件async ctx => { ctx.body = ...}中直接写ctx.body是没有任何问题的,但是不能将ctx.body写在中间件中的某个异步操作之中,这样子会出错。所以在上述代码中ctx.body不会生效。
这么看来,异步操作需要封装成函数,调用时用 await 来等待,完成后再设置ctx.body。在这里对异步操作 multipart.parse 用 Promise 封装后再使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| const multiparty = require('multiparty');
const path = require('path');
const fse = require('fs-extra');
const UPLOAD_DIR = path.resolve(__dirname, "../../", "public/upload");
const getUploadData = (req) => {
return new Promise((resolve, reject) => {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
reject(err)
}
const [chunk] = files.chunk;
const [hash] = fields.hash;
const [fileHash] = fields.fileHash;
const chunkDir = path.resolve(UPLOAD_DIR, 'chunkDir_' + fileHash);
if (!fse.existsSync(chunkDir)) {
await fse.mkdir(chunkDir);
}
try {
await fse.move(chunk.path, `${chunkDir}/${hash}`);
resolve()
} catch (err) {
reject(err)
}
});
})
}
uploadRouter.post('/file', async (ctx, next) => {
await getUploadData(ctx.req)
.then(() => {
ctx.body = {
code: 200,
msg: "Successfully uploaded"
}
})
.catch(() => {
ctx.body = {
code: 500,
msg: "Failed to receive file chunk"
};
})
});
|
404 问题解决。
合并切片
使用整体思路中提到的第二种合并切片的方式,即前端主动通知服务端进行合并
前端
思路:前端接收到所有切片都上传成功的信息后,主动向服务端发送合并请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // 上传切片
const uploadChunks = async () => {
// ...
// 并发请求
await Promise.all(requestList);
// 合并切片(只有所有切片篇都上传成功了才会执行到这里)
+ await mergeRequest();
}
+ // 合并文件请求
+ const mergeRequest = async () => {
+ await request({
+ url: baseUrl + '/merge',
+ headers: {
+ "content-type": "application/json"
+ },
+ data: JSON.stringify({
+ fileName: container.file.name,
+ fileHash: container.hash,
+ size: SIZE
+ })
+ });
+ }
|
Promise.all(requestList); 返回的 Promise 对象如果成功,则表示 requestList 中所有的 Promise 都成功,即所有切片成功上传,然后就可以向服务端发起请求合并了。请求数据包括文件名、文件 hash 和切片大小。
服务端
思路:将所有切片并发写入文件,写入位置根据索引和切片大小来确定,在合并完成后删除保存切片的目录。
前端携带文件名、文件 hash 和切片大小三个字段发送合并文件的请求,那么在服务端首先接收请求数据。
接收请求体数据有两种方案
- 安装 koa-body,可以直接通过
ctx.request.body 获取请求体数据;
- 不使用其他库或者中间件,手动解析。
如果使用第一种方案,那么注意要在需要解析请求体的路由才注入 koaBody ,而不要全局注入,否则 multiparty 无法从 ctx.req 解析到 FormData 的相关数据。
这里使用第二种方案。当请求体的数据格式为 JSON 数据时,无法直接通过 ctx.req.xxx 或者 ctx.request.xxx 获取到请求数据。手动解析的思路是,通过监听 data 和 end 事件来读取请求体数据。其中,data 事件在接收到数据时被触发,end 事件在请求体数据接收完成时被触发。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
function resolvePost (req) {
return new Promise(resolve =>{
let chunk = "";
req.on("data", data => {
chunk += data;
});
req.on("end", () => {
resolve(JSON.parse(chunk));
})
})
}
module.exports = {
resolvePost
}
|
1
2
3
4
|
uploadRouter.post('/merge', async (ctx, next) => {
const data = await resolvePost(ctx.req);
})
|
之后通过解构赋值获取所有参数,拼接出文件合并后保存的路径 filepath ,即 UPLOAD_DIR + fileHash + 后缀名,接着调用 mergeFileChunk 方法合并切片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
function extractExt (filename) {
return filename.slice(filename.lastIndexOf('.'), filename.length);
}
uploadRouter.post('/merge', async (ctx, next) => {
const data = await resolvePost(ctx.req);
const { fileName, fileHash, size } = data;
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`);
await mergeFileChunk(filePath, fileHash, size);
ctx.body = {
code: 200,
msg: "merge seccessful"
}
})
|
mergeFileChunk 方法包含了合并切片的核心代码。在整体思路中提到,关于切片的合并,使用 Nodejs 的读写流( readStream 和 writeStream),对应切片的顺序,将所有切片的流传输到最终文件的流里。实现思路拆解:
相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
const pipeStream = (chunkpath, writeStream) =>
new Promise(resolve => {
const readStream = fse.createReadStream(chunkpath);
readStream.on("end", () => {
fse.unlinkSync(chunkpath);
resolve();
});
readStream.pipe(writeStream);
});
const mergeFileChunk = async (filePath, fileHash, size) => {
const chunkDir = path.resolve(UPLOAD_DIR, 'chunkDir_' + fileHash);
const chunkPaths = await fse.readdir(chunkDir);
chunkPaths.sort((a, b) => a.split('-')[1] - b.split('-')[1]);
await Promise.all(
chunkPaths.map((chunkPath, index) =>
pipeStream(
path.resolve(chunkDir, chunkPath),
fse.createWriteStream(filePath, {
start: index * size
})
)
)
);
fse.rmdirSync(chunkDir)
}
|
为每一个切片都要创建一个新的 writeStream 写入流,需要注意的是,我们给fs.createWriteStream传入了第二个参数start,以此来控制创建可写流的位置,从而达到并发合并多个可读流(pipeStream中通过切片路径创建)到可写流指定位置的目的。这样子,即使并发时,流的顺序不同,也能根据start传输到正确的位置。
显示上传进度条(前端)
单个切片上传进度条
文件上传进度条可以通过 XMLHttpRequest 原生支持监听上传进度来实现,监听 XMLHttpRequest 对象的 upload.onprogress 获取上传进度的信息。所以在原来封装的request请求逻辑基础上,给 XMLHttpRequest 注册监听事件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // src/utils/request.js
const request = ({
url,
method = 'POST',
data,
headers = {},
+ onProgress = e => e
}) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
+ xhr.upload.onprogress = onProgress;
// 拼接完整的请求URL
url = baseUrl + url;
xhr.open(method, url);
// ...
})
}
|
这里的需求是,切片单独上传并需要显示各自的上传进度的,所以触发的监听事件也是独立的,需要一个工厂函数,根据传入切片返回不同的监听函数。新增监听函数的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| // 上传切片
const uploadChunks = async () => {
const requestList = data.value
.map(({ chunk, hash, index }) => {
// ...
return { formData, index }
})
+ .map(({ formData, index }) =>
request({
url: "/file",
data: formData,
+ onProgress: createProgressHandler(data.value[index])
})
);
// 并发请求
await Promise.all(requestList);
// 合并切片(只有所有切片篇都上传成功了才会执行到这里)
await mergeRequest();
}
+ // 单个切片进度条,为每个切片单独新增监听函数
+ const createProgressHandler = (item) => {
+ return e => {
+ item.percentage = parseInt(String((e.loaded / e.total) * 100));
+ };
+ }
// 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
container.hash = await calculateHash(fileChunkList); // 计算文件md5
data.value = fileChunkList.map(({ file }, index) => ({
fileHash: container.hash,
chunk: file,
index,
size: file.size,
hash: container.hash + '-' + index,
+ percentage: 0 // 单个切片的上传进度
}));
await uploadChunks();
} catch (error) {
console.log(error);
}
};
|
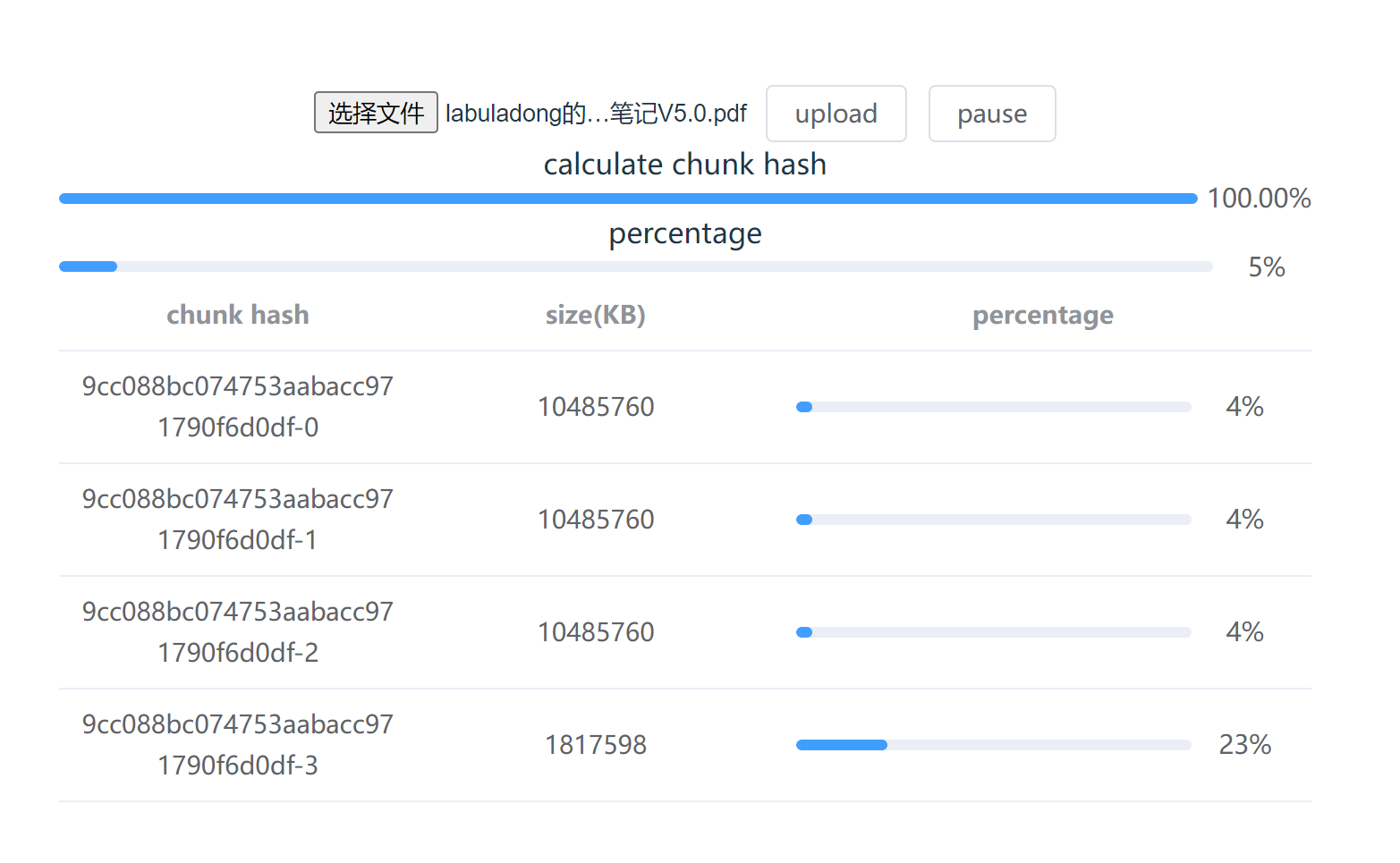
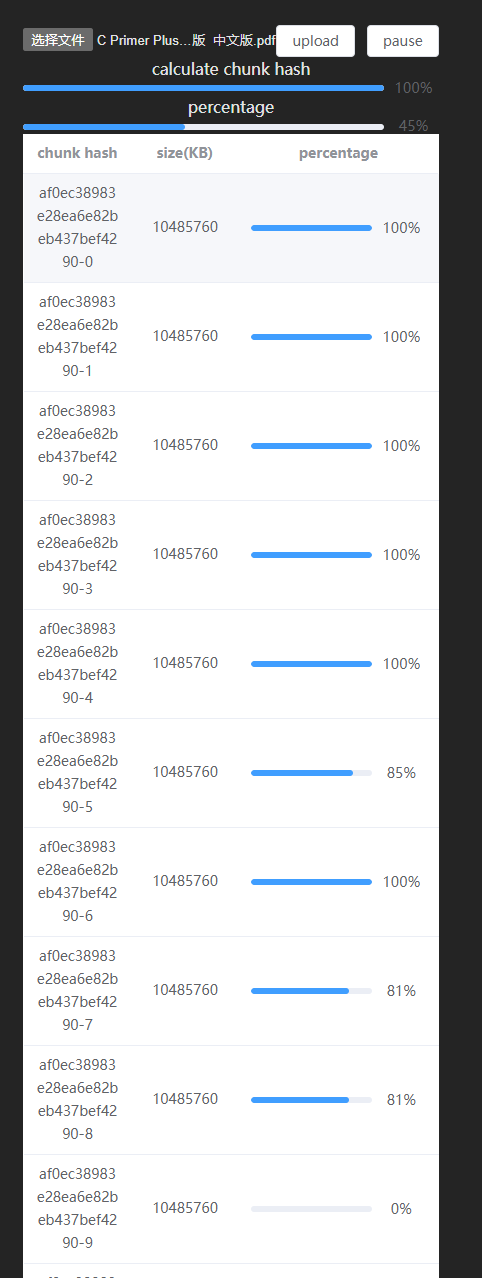
使用table组件展示每个切片的上传情况
1
2
3
4
5
6
7
8
9
| <el-table :data="data" style="width: 100%">
<el-table-column prop="hash" label="chunk hash" align="center" />
<el-table-column prop="size" label="size(KB)" align="center" />
<el-table-column label="percentage" align="center" width="200">
<template v-slot="{ row }">
<el-progress :percentage="row.percentage" />
</template>
</el-table-column>
</el-table>
|
最终展示效果如下:
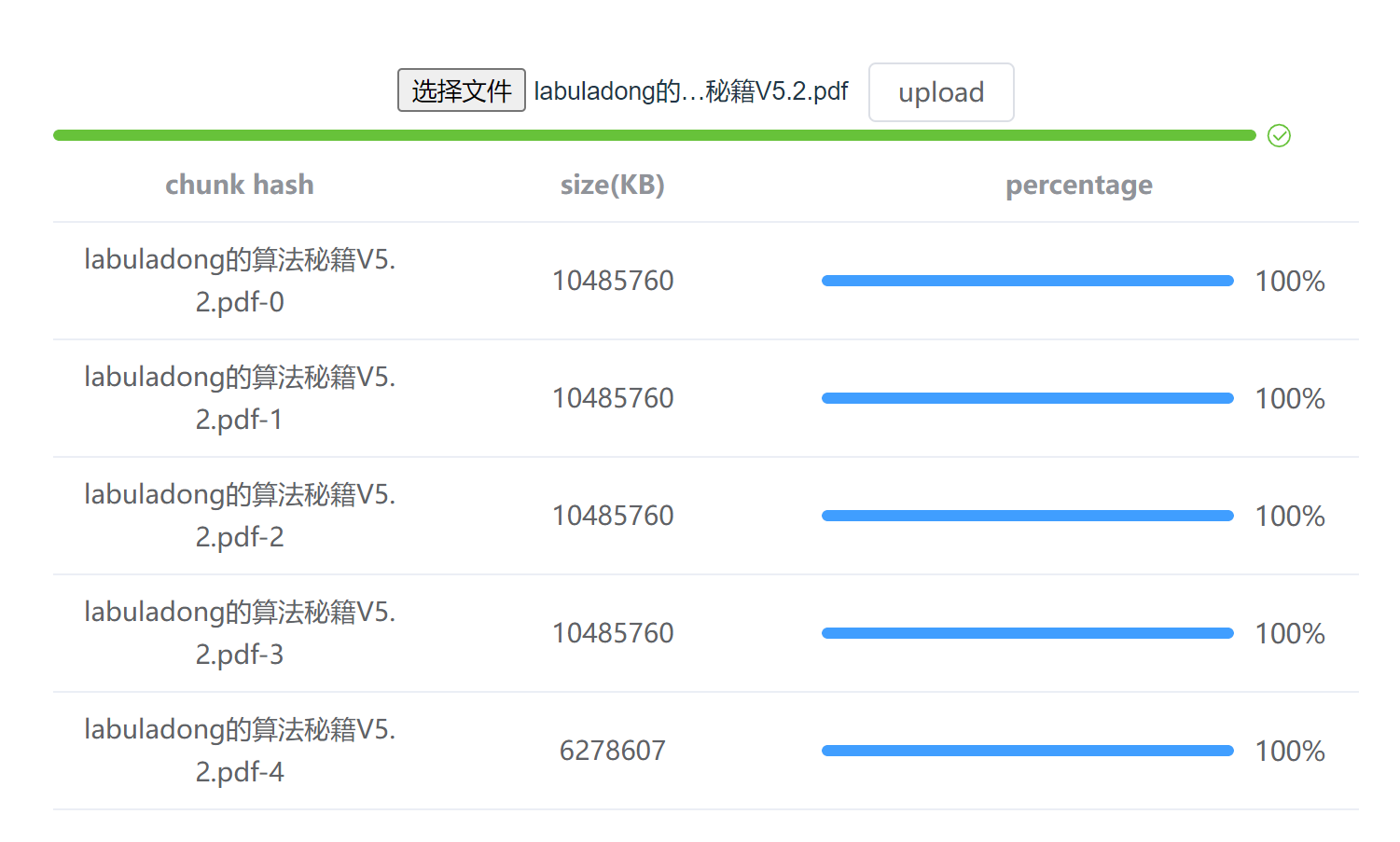
总进度条
将每个切片已上传的部分累加,就是相当于整个文件的以上传部分。这里我们使用计算属性来得出当前文件的上传进度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <template>
<el-progress :percentage="uploadPercentage" :status="uploadPercentage === 100 ? 'success' : ''"/>
</template>
<script setup>
// 总进度条
const uploadPercentage = computed(() => {
if (!container.file || !data.value.length) return 0;
const loaded = data.value
.map(item => item.size * item.percentage)
.reduce((acc, cur) => acc + cur);
return parseInt((loaded / container.file.size).toFixed(2));
})
</script>
|
最后,在选择了新文件后将data置空,初始化进度条状态。
1
2
3
4
5
| const handleFileChange = (e) => {
if (!file) return;
container.file = file;
+ data.value = [];
};
|
文件秒传
文件秒传的原理是通过检查服务端是否已经存在当前文件了,如果已经存在则直接跳过上传的操作。具体根据文件 hash 来判断,前端在调用上传文件的接口前,会先发起一个验证请求,验证服务端是否已存在该 hash 值对应的文件,若是,则直接返回成功上传,若否,则照常上传。
前端
相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| + // 验证文件请求
+ const verifyUpload = async (fileName, fileHash) => {
+ const { data } = await request({
+ url: "/verify",
+ headers: {
+ "content-type": "application/json"
+ },
+ data: JSON.stringify({
+ fileName,
+ fileHash
+ })
+ });
+ return JSON.parse(JSON.parse(data).data);
+ }
// 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
container.hash = await calculateHash(fileChunkList); // 计算文件md5
// 验证文件秒传
+ const { shouldUpload } = await verifyUpload(container.file.name, container.hash);
+ if (!shouldUpload) {
+ return;
+ }
data.value = fileChunkList.map(({ file }, index) => ({
// ...
}));
};
|
服务端
新增验证接口逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| uploadRouter.post('/verify', async (ctx, next) => {
const data = await resolvePost(ctx.req);
const { fileName, fileHash } = data;
const ext = extractExt(fileName);
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`);
if (fse.existsSync(filePath)) {
ctx.body = {
code: 200,
data: JSON.stringify({
shouldUpload: false
})
};
} else {
ctx.body = {
code: 200,
data: JSON.stringify({
shouldUpload: true
})
}
}
})
|
断点续传
断点续传的原理在于前端/服务端需要记住已上传的切片,以便于在下一次上传的时候跳过已经上传的部分。基于前端记忆(localStorage)的方案在切换浏览器后会失去记忆功能,所以我们使用服务端记忆的方案,前端每次上传前都向服务端获取已上传的切片。
两者实现的逻辑其实是基本相似的,都是根据已上传切片的记录,在上传前剔除,上传后保存记录
暂停上传
前端
暂停上传,实现“断点”。原理是使用 XMLHttpRequest 的abort方法,取消 xhr 请求的发送,因此我们需要将上传每个切片的xhr对象保存起来,然后进行操作。
在原有的请求逻辑上添加相关代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| // src/utils/request.js
const request = ({
url,
method = 'POST',
data,
headers = {},
onProgress = e => e,
+ xhrList // 保存所有xhr请求
}) => {
return new Promise((resolve, reject) => {
// ...
xhr.onload = e => {
if (xhr.status >= 200 && xhr.status < 300) {
+ // 当前 xhr 成功后,从 xhrList 中移出
+ if (xhrList) {
+ const xhrIndex = xhrList.findIndex(item => item === xhr);
+ xhrList.splice(xhrIndex, 1);
+ }
resolve({
data: e.target.response
});
} else {
reject(new Error(`Request failed with status ${xhr.status}`));
}
};
xhr.onerror = () => {
reject(new Error('Network error'));
};
+ // 暴露当前xhr给外部
+ xhrList?.push(xhr);
})
}
|
声明变量xhrList,只有在发起上传切片的请求时才需要传入xhrList,使得所有上传切片的请求保存在xhrList中。
创建xhr请求的时候,将其添加到传入的参数xhrList中保存起来,触发onload事件请求成功后,将其从xhrList中移除,使得xhrList中只保存正在上传切片的xhr。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| + let xhrList = [];
// 上传切片
const uploadChunks = async () => {
const requestList = data.value
.map(({ chunk, hash, index }) => {
// ...
})
.map(({ formData, index }) =>
request({
url: "/file",
data: formData,
onProgress: createProgressHandler(data.value[index]),
+ xhrList
})
);
// ...
}
|
添加按钮组件,触发暂停上传事件,取消并清空xhrList中所有请求。
1
2
3
4
5
6
7
8
9
10
| <template>
<el-button @click="handlePause">pause</el-button>
</template>
<script setup>
// 暂停上传
const handlePause = async () => {
xhrList.forEach(xhr => xhr?.abort());
xhrList = [];
}
</script>
|
服务端
处理一下取消xhr请求的报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 接收文件
const getUploadData = (req) => {
return new Promise((resolve, reject) => {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
+ if (req.aborted) { // 检测请求是否被中止
+ console.log('Request aborted');
+ return reject(); // 中止进一步的处理
}
// ...
});
})
}
|
恢复上传
恢复上传的整体思路是,前端在每次上传之前,都会预先调用一个接口,获取服务端已上传的切片名,从而跳过这些切片,只上传服务端没有的切片。将这个接口和之前实现秒传的验证接口进行合并,响应数据包括 ①服务端是否存在该文件;②服务端已上传的切片名。可能的结果有两种:
- 服务端已存在该文件,不需要再次上传
- 服务端不存在该文件或者已上传部分文件切片,通知前端进行上传,并把已上传的文件切片名返回给前端
前端
添加按钮组件,触发恢复上传事件,获取已上传的切片名,传给上文已经实现的处理上传切片逻辑的函数 uploadChunks,将这些切片进行上传。
1
2
3
4
5
6
7
8
9
10
| <template>
<el-button @click="handleResume">resume</el-button>
</template>
<script setup>
// 恢复上传
const handleResume = async () => {
const { uploadedList } = await verifyUpload(container.file.name, container.hash);
await uploadChunks(uploadedList);
}
</script>
|
上传切片逻辑修改如下,发送上传切片的请求之前,先过滤掉uploadedList中包含的已上传的切片,其中对象数组data存储的是全部切片的信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| + const uploadChunks = async (uploadedList = []) => {
const requestList = data.value
+ .filter(({ hash }) => !uploadedList.includes(hash))
.map(({ chunk, hash, index }) => {
// ...
})
.map(({ formData, index }) =>
// ...
})
);
// 并发请求
await Promise.all(requestList);
+ // 之前已上传切片数量 + 本次上传切片数量 = 切片总数时,才发送合并请求
+ if (uploadedList.length + requestList.length === data.value.length) {
+ await mergeRequest();
+ }
}
|
在此之前,requestList表示上传所有切片的结果,是一个promise数组,所以在所有上传请求成功后,直接调用合并请求mergeRequest。但是修改后,requestList表示本次上传切片的情况,并不一定包含所有切片。所以合并请求只发生在本次上传数量与之前上传切片数量之和等于切片总数的时候。
另外,handleUpload 方法中调用了uploadChunks方法,同样新增uploadedList传参。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // 上传文件
const handleUpload = async () => {
try {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
container.hash = await calculateHash(fileChunkList); // 计算文件md5
// 验证文件秒传
+ const { shouldUpload, uploadedList } = await verifyUpload(container.file.name, container.hash);
if (!shouldUpload) {
return;
}
// data.value = ...
+ await uploadChunks(uploadedList);
} catch (error) {
console.log(error);
}
};
|
服务端
服务端需要修改验证接口,根据文件 hash 值,找到切片目录下所有已上传的切片名称,并返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| + // 直接获取 fileHash 对应的切片文件夹路径
+ const getChunkDir = (fileHash) => path.resolve(UPLOAD_DIR, 'chunkDir_' + fileHash);
+ // 返回已上传的所有切片名
+ const createUploadedList = async fileHash =>
+ fse.existsSync(getChunkDir(fileHash)) ? await fse.readdir(getChunkDir(fileHash)) : [];
fileRouter.post('/verify', async (ctx, next) => {
// ...
if (fse.existsSync(filePath)) {
// ...
} else {
ctx.body = {
code: 200,
data: JSON.stringify({
shouldUpload: true,
+ uploadedList: await createUploadedList(fileHash)
})
}
}
|
进度条改进(前端)
此时当我们暂停上传,又恢复上传,会发现进度条出现偏差。
单个切片上传进度条
如果在点击暂停上传按钮后,直接再次通过点击恢复上传按钮,那么已经成功上传了的切片进度条会保持 100% 不变,其他未上传到服务端的切片会从 0 开始,因为重新创建requestList,为需要上传的每个切片从新增加监听函数。
但是如果刷新页面后再点击恢复上传按钮重新上传该文件,那么已经成功上传了的切片进度条会保持 0% 不变,这是因为没有对该切片进行上传,所以无法监听到上传进度,所以需要直接将它们的进度初始化为 100%。
对此作出修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // 上传文件
const handleUpload = async () => {
try {
data.value = fileChunkList.map(({ file }, index) => ({
fileHash: container.hash,
chunk: file,
index,
size: file.size,
hash: container.hash + '-' + index,
+ percentage: uploadedList.includes(container.hash + '-' + index) ? 100 : 0 // 单个切片上传进度
}));
await uploadChunks(uploadedList);
} catch (err) {
console.error(err);
}
};
|
总进度条
回顾一下之前代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <template>
<el-progress :percentage="uploadPercentage" :status="uploadPercentage === 100 ? 'success' : ''"/>
</template>
<script setup>
// 总进度条
const uploadPercentage = computed(() => {
if (!container.file || !data.value.length) return 0;
const loaded = data.value
.map(item => item.size * item.percentage)
.reduce((acc, cur) => acc + cur);
return parseInt((loaded / container.file.size).toFixed(2));
})
</script>
|
在这里我们使用了计算属性,根据 data 中所有切片的上传进度来计算总上传进度。当我们暂停上传然后重新恢复上传时,未上传完毕的切片进度会直接清零,这导致了总进度条会因此出现倒退。为了观感好一点,设置总进度条的规则是只能暂停和新增,不能倒退。
新增监听 uploadPercentage 变化的逻辑,只有当uploadPercentage出现新增了,才更新fakeUploadPercentage。
1
2
3
4
5
6
7
8
9
10
11
12
| <template>
<el-progress :percentage="fakeUploadPercentage" :status="fakeUploadPercentage === 100 ? 'success' : ''" />
</template>
<script setup>
let fakeUploadPercentage = ref(0);
watch(uploadPercentage, (now) => {
if (now > fakeUploadPercentage.value) {
fakeUploadPercentage.value = now;
}
});
</script>
|
改进&拓展
主要参考文章: 字节跳动面试官,我也实现了大文件上传和断点续传
时间切片计算文件hash
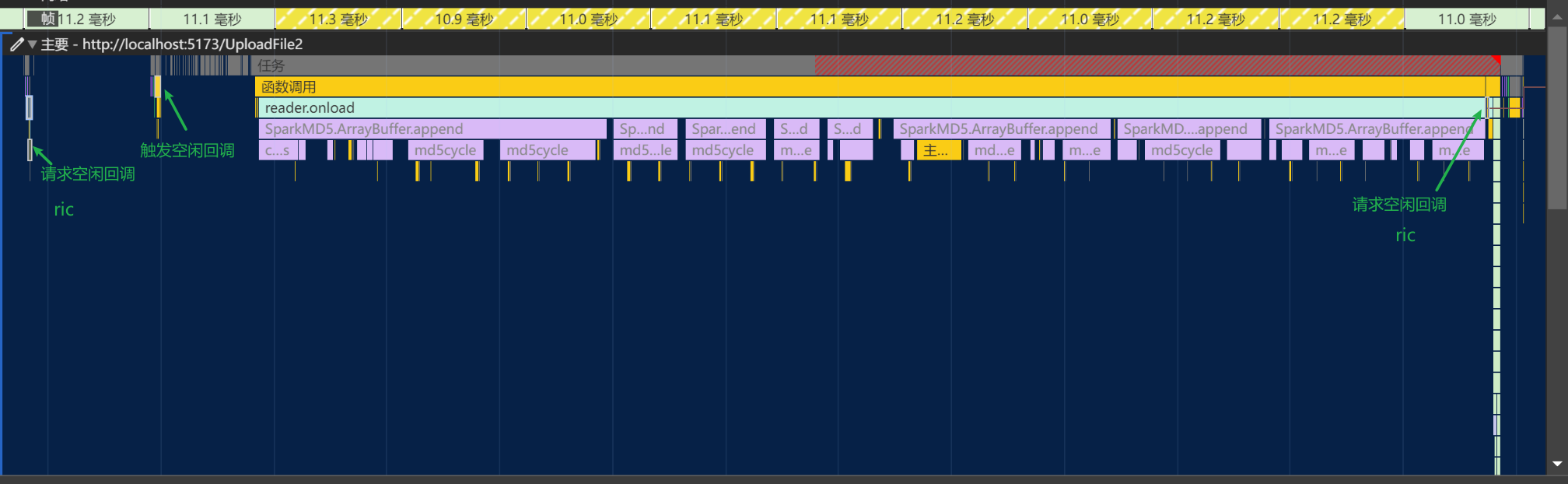
计算文件 hash 耗时的问题,除了通过 web-worker,还可以通过requestIdleCallback函数,利用浏览器的空闲时间计算 hash,也不会阻碍主线程。它允许开发人员在主事件循环中执行后台和低优先级任务,而不影响一些延迟关键事件。该函数接受一个deadline参数,字段结构如下:
didTimeout: boolean,表示任务执行是否超过约定时间timeRemaining(): DOMHighResTimeStamp,表示任务可供执行的剩余时间

在上面的两帧中,idle period就是表示每一帧的空闲时间,deadline.timeRemaining()获取的就是所在帧任务执行结束后到所在帧结尾的时间(ms级)。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import SparkMD5 from 'spark-md5'
const calculateHash = fileChunkList => {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
const appendToSpark = async file => {
return new Promise(resolve => {
const reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = e => {
spark.append(e.target.result);
resolve();
};
});
};
const workLoop = async deadline => {
while (count < fileChunkList.length && deadline.timeRemaining() > 1) {
await appendToSpark(fileChunkList[count].file);
count++;
if (count < fileChunkList.length) {
hashPercentage.value = Number(
((100 * count) / fileChunkList.length).toFixed(2)
);
} else {
hashPercentage.value = 100;
resolve(spark.end());
}
}
window.requestIdleCallback(workLoop);
};
window.requestIdleCallback(workLoop);
})
}
|
疑问说明
MDN 相关文档提到
- 空闲回调必须避免执行
Promise的 resolve 和 reject,因为这会在你的回调函数返回后立即引用 Promise 对象对 resolve 和 reject 的处理程序。
所以这里的应用感觉不太对。
性能面板,当切片大小为 10MB 时,空闲回调表现大致如下:
抽样hash
标识文件的 hash 值原理是根据文件内容计算 md5 值,显然文件越大,耗时越长。参考布隆过滤器的理念,对文件内容进行抽样计算 hash,思路如下
文件切片大小设为 2MB(这里指的是抽样算hash的文件切片,而不是用作上传的切片)
第一个和最后一个切片取全部内容,其他切片的取首中尾三个地方各2个字节
合并抽样内容,计算 md5
根据最终 hash 的结果实现秒传,结果有两种:“一定不存在”或者“可能存在(小概率误判)”。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
const calculateHashSample = async () =>{
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReader();
const file = container.file;
const size = container.file.size;
let offset = 2 * 1024 * 1024;
let chunks = [file.slice(0, offset)];
let cur = offset;
while (cur < size) {
if (cur + offset >= size) {
chunks.push(file.slice(cur, cur + offset));
} else {
const mid = cur + offset / 2;
const end = cur + offset;
chunks.push(file.slice(cur, cur + 2));
chunks.push(file.slice(mid, mid + 2));
chunks.push(file.slice(end - 2, end));
}
cur += offset;
}
reader.readAsArrayBuffer(new Blob(chunks));
reader.onload = e => {
spark.append(e.target.result);
resolve(spark.end());
};
});
}
const handleUpload = async () => {
if (!container.file) return;
const fileChunkList = createFileChunk(container.file, SIZE);
container.hash = await calculateHashSample()
};
|
尝试上传一个 1G 左右的文件,全量大概 13 秒,抽样大概 500 毫秒。
网络请求并发控制
目的是为了避免上传大文件时 http 请求过多把浏览器卡死。在原本的思路中,是通过遍历所有切片的 formData 然后全量并发,全部请求同时发起。现在是先收集好 formData,通过 max 维护可请求的通道数,即并发数。在 max > 0 时允许发起请求并执行 max-- ,请求结束后 max++。
代码实现
将控制请求并发的函数 sendRequest 一同封装在 request.js 文件中,顺带把 createProgressHandler 逻辑一起移过来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| // src/utils/request.js
const baseUrl = "http://localhost:8080/upload";
export const request = ({
url,
method = 'POST',
data,
headers = {},
onProgress = e => e,
xhrList // 保存所有xhr请求
}) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.upload.onprogress = onProgress;
// 拼接完整的请求URL
url = baseUrl + url;
xhr.open(method, url);
Object.keys(headers).forEach(key => xhr.setRequestHeader(key, headers[key]));
xhr.send(data);
xhr.onload = e => {
if (xhr.status >= 200 && xhr.status < 300) {
// 当前 xhr 成功后,从 xhrList 中移出
if (xhrList) {
const xhrIndex = xhrList.findIndex(item => item
xhrList.splice(xhrIndex, 1);
}
resolve({
data: e.target.response
});
} else {
reject(new Error(`Request failed with status ${xhr.status}`));
}
};
xhr.onerror = () => {
reject(new Error('Network error'));
};
// 暴露当前xhr给外部
xhrList?.push(xhr);
})
}
+ // 网络请求并发控制
+ export const sendRequest = (formList, max, dataList, xhrList) => {
+ return new Promise((resolve, reject) => {
+ max = max || 4; // 请求并发度默认为4
+ let idx = 0, count = 0;
+ const len = formList.length; // 请求总数
+ const start = async () => {
+ // 有请求,有通道
+ while (idx < len && max > 0) {
+ max--; // 占用通道
+ const formData = formList[idx].formData;
+ const index = formList[idx].index;
+ idx++;
+ request({
+ url: "/file",
+ data: formData,
+ onProgress: createProgressHandler(dataList[index]),
+ xhrList
+ }).then(() => {
+ max++; // 释放通道
+ count++;
+ if (count === len) {
+ // console.log('全部请求结束');
+ resolve()
+ } else {
+ start();
+ }
+ })
+ }
+ }
+ start();
+ })
+ }
+ // 单个切片进度条,为每个切片单独新增监听函数
+ const createProgressHandler = (item) => {
+ return e => {
+ item.percentage = parseInt(String((e.loaded / e.total) * 100));
+ };
+ }
|
请求并发
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| + import { request, sendRequest } from "./../utils/request";
// 上传切片
const uploadChunks = async (uploadedList = []) => {
const formList = data.value
.filter(({ hash }) => !uploadedList.includes(hash))
.map(({ chunk, hash, index }) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("hash", hash);
formData.append("fileHash", container.hash);
formData.append("filename", container.file.name);
return { formData, index }
})
- .map(({ formData, index }) =>
- request({
- url: "/file",
- data: formData,
- onProgress: createProgressHandler(data.value[index]),
- xhrList
- })
- );
- // 全量并发请求
- await Promise.all(requestList);
// 控制并发请求
+ await sendRequest(formList, 4, data.value, xhrList)
// 之前已上传切片数量 + 本次上传切片数量 = 切片总数时,才发送合并请求
if (uploadedList.length + formList.length
await mergeRequest();
}
}
|
并发重试+报错
思路:允许在切片文件上传发生错误的话,可以重试2次,若三次请求都发生错误,那么文件上传失败。实现思路是基于上文“网络请求并发控制”实现,添加 .catch 方法处理上传请求失败的情况,对于这类错误的请求,记录其重试次数,在达到重试上限之前,都可以重新发起请求。
首先我们在服务端模拟上传出现错误的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| // src/router/upload.js
// multipart 解析请求体FormData
const getUploadData = (req) => {
return new Promise((resolve, reject) => {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
+ if (Math.random() < 0.05) {
+ reject()
+ }
// ...
});
})
}
// 上传文件
uploadRouter.post('/file', async (ctx, next) => {
await getUploadData(ctx.req)
.then(() => {
ctx.body = {
code: 200,
msg: "Successfully uploaded"
}
})
+ .catch((fileIndex) => {
+ ctx.status = 500
+ ctx.body = {
+ code: 500,
+ msg: "Failed to receive file chunk"
+ };
+ })
+ });
|
前端这边,为了能够实现重试失败的请求,并且重试次数有限,显然需要新增变量记录请求的当前状态和重试情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| // src/utils/request.js
// 定义常量规定请求状态的类别
+ const Status = {
+ done: 'done',
+ error: 'error',
+ wait: 'wait',
+ uploading: 'uploading'
+ }
// 网络请求并发控制
export const sendRequest = (formList, max=4, dataList, xhrList) => {
return new Promise((resolve, reject) => {
let count = 0;
const len = formList.length; // 请求总数
// 统计每个请求的重发次数
+ const retryArr = new Array(formList.length).fill(0);
const start = async () => {
// 有请求,有通道
+ while (count < len && max > 0) {
max--; // 占用通道
+ // 任务不能仅仅累加获取(原来是直接取idx++),而是要根据请求状态,所以while循环条件也要是count < len
+ // 找到第一个等待或者失败的请求,这个时候即使找的是失败的请求也是请求次数没有超过3次的,不然早就reject出去一整个上传请求都会失败
+ // 这里的 idx ≠ formList中切片元素的真实下标,因为之前formList有过滤操作
+ const idx = formList.findIndex(v => v.status == Status.wait || v.status == Status.error);
// 有可能已经没有等待发送的请求了
+ if (idx == -1) {
+ return;
+ }
+ formList[idx].status = Status.uploading; // 发起对formList[idx]的请求
const formData = formList[idx].formData;
const index = formList[idx].index;
+ // 可以通过retryArr[index]判断当前切片的以往发送记录
+ // if (retryArr[index] === 0) {
+ // console.log(`切片${index}开始发起`);
+ // }else {
+ // console.log(`切片${index}第${retryArr[index]++}次发起`);
+ // }
request({
url: "/file",
data: formData,
onProgress: createProgressHandler(dataList[index]),
xhrList
}).then(() => {
+ // 请求成功,修改formList相关切片的请求状态为成功
+ formList[idx].status = Status.done;
max++; // 释放通道
count++;
if (count
// console.log('全部请求结束');
resolve()
} else {
console.log(`切片${index}上传成功`)
start();
}
+ }).catch(err => {
+ // 请求失败,修改formList相关切片的请求状态为失败
+ formList[idx].status = Status.error;
+ // 累加切片formList[idx]的发送情况
+ retryArr[idx]++;
+ // 当该请求报错超过三次,则直接结束,否则可以进行重试
+ if (retryArr[idx] >= 3) {
+ console.log(`切片${index}超过重试次数`)
+ dataList[index].percentage = 0; // 报错的进度条重置
+ return reject();
+ }
+ console.log(`切片${index}第${retryArr[idx]}次报错`)
+ dataList[index].percentage = 0; // 报错的进度条重置
+ max++;
+ start();
})
}
}
start();
})
}
|
回顾前文实现的文件上传逻辑,uploadChunks 方法用来根据全部切片文件的相关数据 data 数组发起上传请求。在“控制并发请求”时,采用 idx 递增的方式,挨个操作 formList 的数据。因此对于每个切片请求状态,我们将这个变量初始化在 formList 的每个元素中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // src/views/UploadFile.vue
// 上传切片
const uploadChunks = async (uploadedList = []) => {
const formList = data.value
.filter(({ hash }) => !uploadedList.includes(hash))
.map(({ chunk, hash, index }) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("hash", hash);
formData.append("fileHash", container.hash);
formData.append("filename", container.file.name);
+ const status = 'wait';
+ return { formData, index, status }
})
// 控制并发请求
await sendRequest(formList, 4, data.value, xhrList)
// 之前已上传切片数量 + 本次上传切片数量 = 切片总数时,才发送合并请求
if (uploadedList.length + formList.length
await mergeRequest();
}
}
|
具体实现思路可看代码注释。
思考和总结
难点
切片的大小:太小的分片会增加请求次数,影响效率;太大的分片可能导致内存占用过高,甚至上传失败
网络资料:服务器端都会有个固定大小的接收Buffer。分片的大小最好是这个值的整数倍。推荐2M-5M
【慢启动策略实现】根据当前网络情况,动态调整切片的大小。
网络稳定性和重试机制
分片上传顺序和重组
注意。重组文件后,有必要进行一次完整性校验确保内容正确,可以通过比对文件的大小、hash值等方式来实现
对于切片的合并,两种方案:
(1)当服务端根据前端传过来的信息,在接受切片到最大数量时自动合并。
(2)前端额外发一个请求,主动通知服务端进行切片的合并。(上文实现)
并发上传的控制:并发上传分片可以提高效率,但是过多的并发可能会导致浏览器或服务器端资源压力增大,因此往往需要一套机制来限制并发请求数
对于 HTTP1.1 ,上传分片的请求会进入一个排队,占用掉后面所有的请求,也就是说之后的请求都要在全部分片都上传完后才能正常发出
对于 HTTP2,虽然实现了多路复用,但是大量的请求同时发出也会占用 cpu ,造成阻塞,所以这里就需要用到并发控制了
断点续传:在断网或其他上传中断的情况后,从中断的地方继续上传
前端方案:将切片索引、md5、切片内容存储到 indexdb,可以方便实现在页面刷新后重新上传。注意有副作用,同时这也是占用存储的,需要清理。
服务器端方案(上文):前端每次上传前都向服务端获取已上传的切片,在前端将这些切片过滤掉再发起上传请求
服务器资源消耗:服务器端需要处理大量的并发请求和大文件的重组,这可能会对服务器资源造成较大的消耗
【文件碎片清理】通过 node-schedule 管理定时任务,清理掉无用的文件碎片
前端资源占用:在前端进行文件切片处理时可能会占用大量的内存,特别是在处理超大文件时,可采用的方案如下,反正就是不要一次性来读这个文件,或者提前限制文件大小。
可以考虑流式处理文件(用流来读取和写入)
分布加载文件
限制文件上传大小
文件上传前可以先zip压缩,减小体积
用户体验:如何在不影响用户体验的情况下分片,比如上传进度的显示和错误处理
跨浏览器兼容性
待优化方向
- websocket 提速
- 动态确定切片大小 + 并行
- 进度条可以再继续优化,在上文经过“并发重试+报错”实现后,进度条有时并不那么准确
参考文章